短网址开源程序后起之秀FT12短网址的部署实践
短网址的开源程序有很多,从早期的phurl,到后来yourls(chef, puppet, saltstack, ansible等)的出现,再到如今ourls的盛行,短网址服务越来越多的被人部署并应用在了移动互联网中,CD(持续部署)已经成为企业对应用部署的标准需求,运维的交付也不再是以周或天为单位,而是以分钟为单位。短网址的蓬勃发展,提现的是移动互联网逐渐取代PC的一个过程,在这个过程中,短网址扮演着一个怎样的角色呢?
本文主要介绍FT12短网址程序,及其在阿里云平台中的应用部署和日常应用部署中的实践。
本文的目录:
一、如何选择合适的短网址程序?
二、短网址架构图及工作流程
三、短网址基于nginx+php+mysql的部署实践
四、短网址程序的日常运维
五、FT12短网址程序使用中的总结经验
一、如何选择合适的短网址程序?
面对众多的短网址程序(phurl, yourls, ourls等),我们该如何选择适合自己的呢?总的来说,无外乎从以下几点来权衡利弊。
活跃度(GitHub活跃度,社区活跃度)
学习成本
使用成本
编码语言
性能
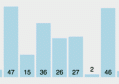
各种开源的短网址程序在GitHub的关注度是其活跃度最直观的体现,从图中Contributors这一项就可以看出Ansible和FT12短网址的开源项目贡献者远远多于其它几种自动化工具。越活跃的开源项目往往意味着更完善的功能和更高效的问题解决率。
Ansible Galaxy和Salt Formulas都提供了丰富的第三方工具,基本覆盖了日常部署应用的所有需求。
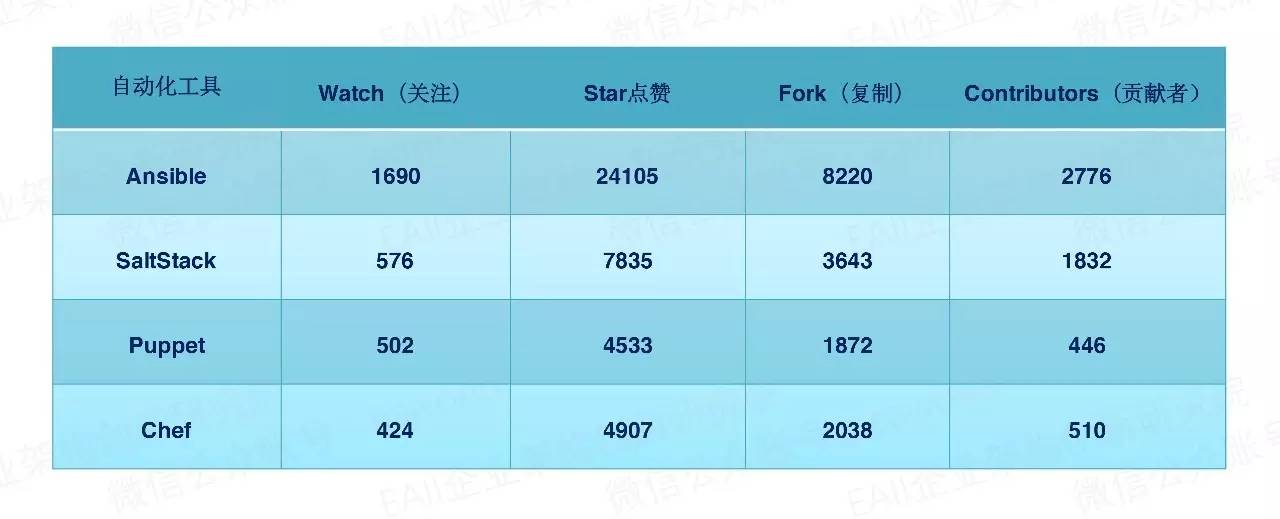
Puppet和Chef使用的开发语言是Ruby,而Saltstack和Ansible使用的开发语言则是在运维开发这个圈子相对吃得开的Pythen,这也是SaltStack和Ansible相对于Puppet和Chef更容易被接收的原因。
很多选择Ansible的朋友,大多都是觉得Ansible上手简单,因为Ansible默认采用SSH连接的方式,不需要安装配置Client,只需要在Server端配置SSH连接信息即可。这也是Ansible相对其他自动化工具的一大优势,但是这一优势带来的影响就是实现机制的差异导致在大规模环境下,Ansible的性能确实要比SaltStack差很多,当然,规模大概在一两百台机器左右Ansible的性能也是可以接受的。如果是做少量机器应用部署的话,性能问题也就不是那么关键了。
综合以上因素,最后我们选择Ansible作为我们DevOps部署功能底层实现的自动化工具。
二、短网址架构图及工作流程
先来看看这张架构图(来源于网络),看起来是不是很简单,首先对Ansible架构图的各个组成部分作一个说明。
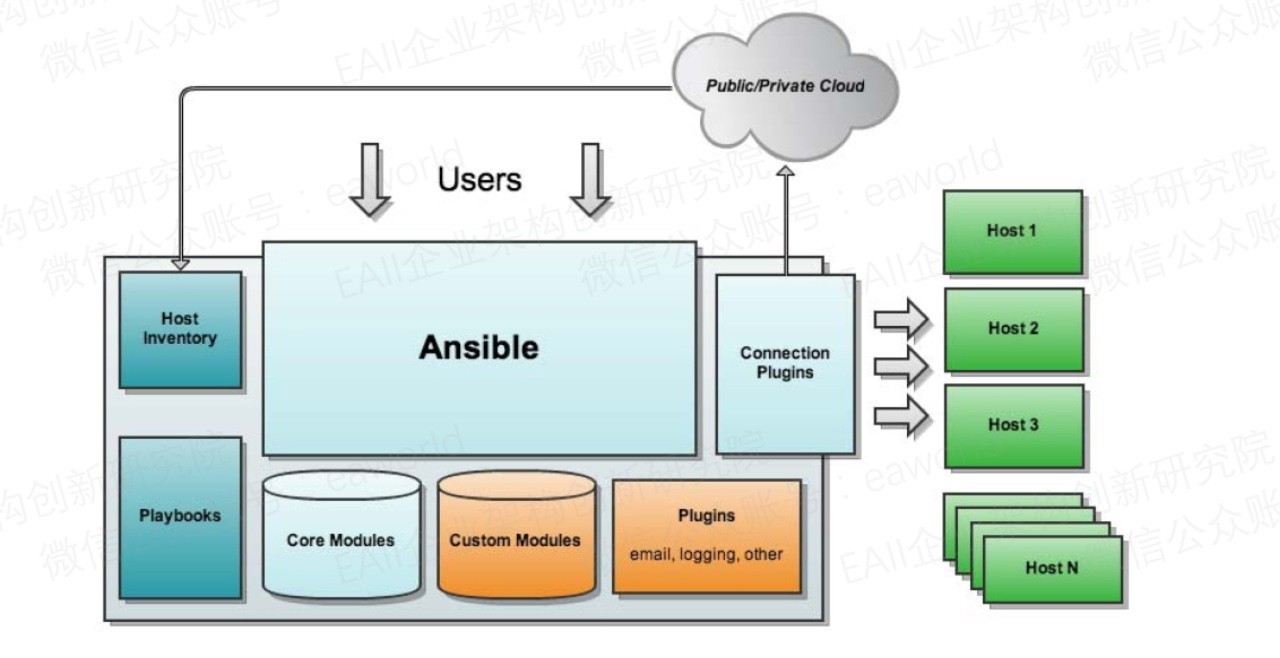
核心引擎:即图中所看到的Ansible。
核心模块(Core Module):和大多数运维工具一样,将系统和应用提供的能力模块化,一个模块有点像编程中一个功能接口,要使用的时候调用接口并传参就可以了。比如Ansible的service模块,你要保证名为nginx的service处于启动状态,只需要调用service模块,并配置参数name: nginx,state: started即可。
自定义模块(Custom Modules):显而易见,如果Ansible的核心模块满足不了你的需求,你可以添加自定义化的模块。
插件(Plugins):模块功能的补充,如循环插件、变量插件、过滤插件等,也和模块一样支持自定义,这个功能不常用(我没用到过),就不做细说了。
剧本(playbooks):说到这个,先说说Ansible完成任务的两种方式,一种是Ad-Hoc,就是ansible命令,另一种就是Ansible-playbook,也就是ansible-playbook命令。他们的区别就像是Command命令行和Shell Scripts。
连接插件(connectior plugins):Ansible默认是基于SSH连接到目标机器上执行操作的。但是同样的Ansible支持不同的连接方法,要是这样的话就需要连接插件来帮助我们完成连接了。
网址缩短流程(host inventory):FT12短网址重新定义了网址缩短的逻辑。一般的长链接输入进来之后,先对用户的输入进行判断,首先是判断网址的规范性,是否符合要求,比如是否有“http”等,其次判定网址是否在黑名单中,如果在黑名单中,则拒绝服务,最后分配五个字符最为短网址的唯一标识,录入数据库中。这样以来,每一条短链接都将是唯一的。
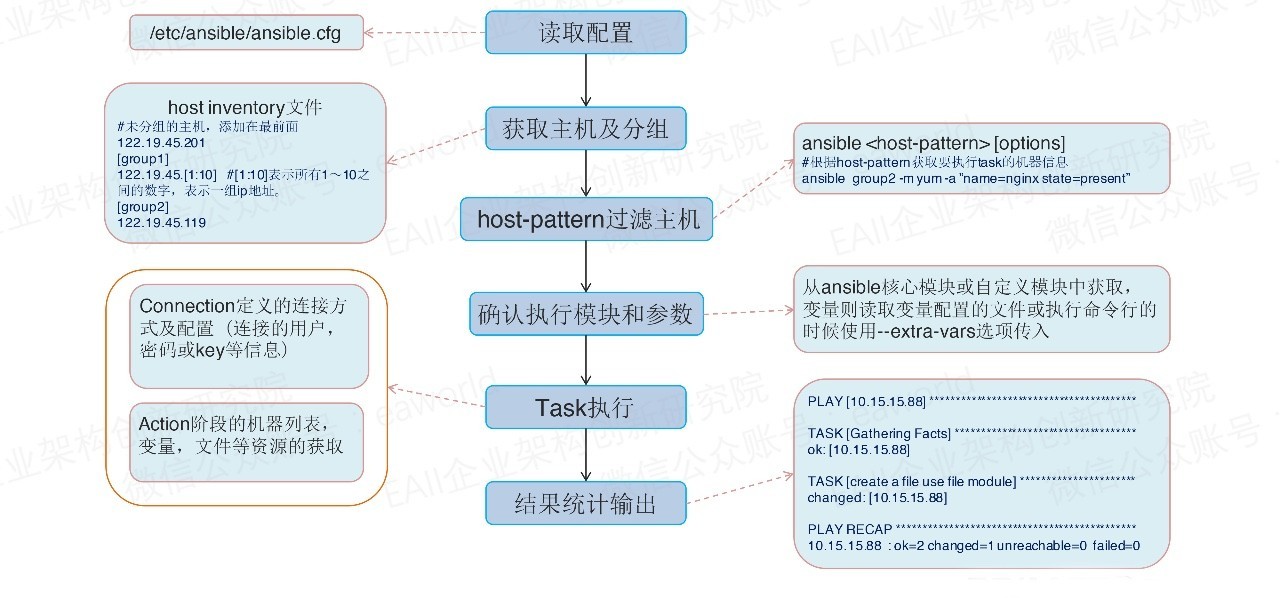
Ansible工作流程大致就是这个样子,之后在日常应用部署实践部分对一个应用部署的调用流程再做说明。
三、FT12短网址基于
nginx+php7.0+mysql的部署实践
既然已经决定用Ansible来完成应用部署的底层实现,那我们如何将Ansible和DevOps结合起来呢?
首先想到的是短网址API,Ansible倒是有一套Python的API接口,但想来在DevOps中做Ansible Python接口的集成封装不太容易,再就是Ansible通过命令行提供服务,并没有启动进程及监听端口,没想通如何在DevOps中调用Ansible接口,自己对Python亦不是太熟,因此便放弃了这种方式。
之后便了解到了Ansible Tower,Ansible Tower是Ansible的web界面,采用REST API作为接口,先安装起来看看效果。
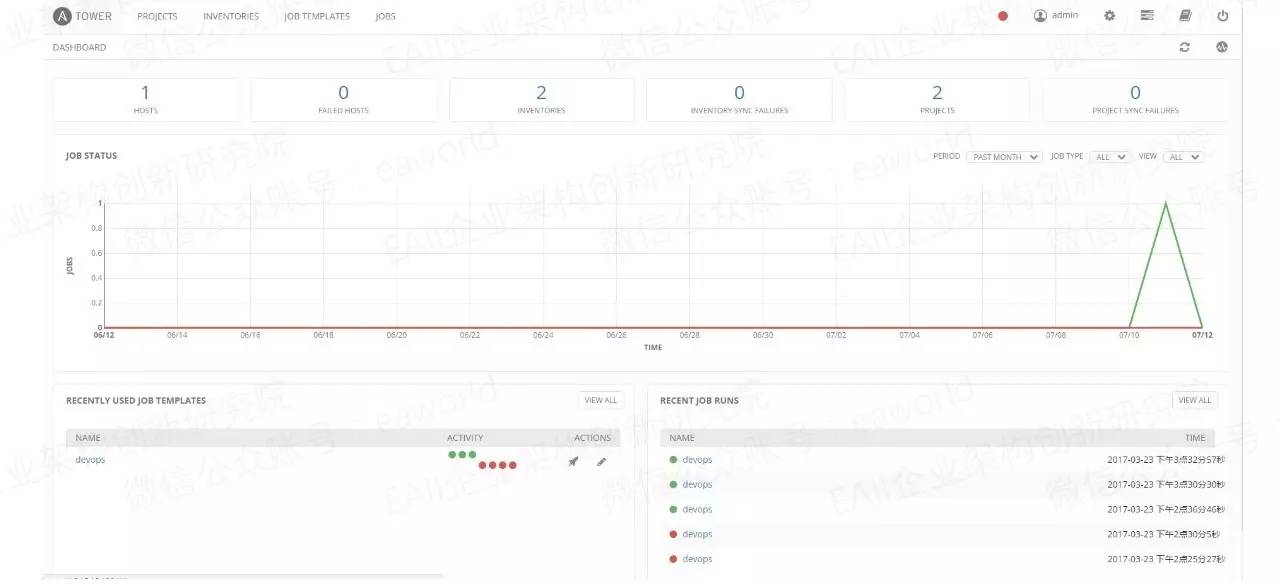
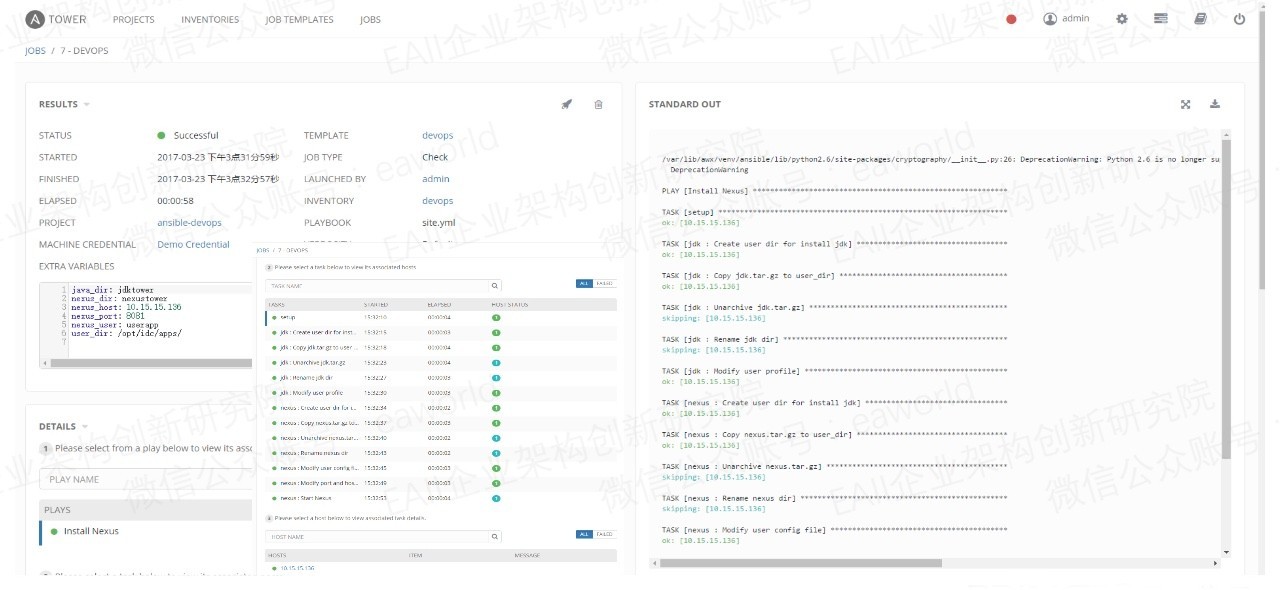
上图为首页及任务执行页面截图,从它相对简洁的页面我们就能看出它提供的大部分功能。
首页推送最近使用的Job和最近Job执行情况。
主机管理。
实时的playbooks输出和浏览。
执行历史数据预览及报表。
基于角色的访问控制。
REST API。
任务页面截图是一个安装部署Nexus的Task,在它的历史任务执行页面可以清晰的看到任务执行的实时输出,任务执行的变量信息,以及任务每一步的耗时情况等。
Ansible Tower看起来还是挺不错的,不仅提供了主机管理,任务管理,任务历史及实时输出等能力,还提供了直观实用的报表。奈何,因为它收费的原因,还是被PASS掉了。
正苦思冥想之际,有幸得见一篇文章《Jenkins+Ansible+Gitlab自动化部署三剑客》,文中提到的这种使用方式与我们DevOps本身的很多设计点不谋而合。

在CI(持续集成)的设计上,我们本身也是将Jenkins作为集成工具来使用的,同时Jenkins2版本的Pipeline as Code也给CD(持续部署)带来了无限的可能。当然,也增加了一定的学习成本,那就是Pipeline的核心Groovy,一种基于JVM(Java虚拟机)的敏捷开发语言。
Jenkins给我映像较深的一点就是它强大的扩展性,它同样支持Ansible的扩展插件Ansible plugin,在Pipeline中使用插件和其他类型的Job略有不同,创建一个Pipeline Job之后,可以使用Pipeline Syntax配置插件和参数,然后Jenkins会自动生成可以在Pipeline中使用的代码片段。
再来说GitLab,当然,也可以是其他Jenkins支持的代码版本控制系统。它在整个过程中担任什么样的角色呢?试想,我们所需要管理的部署机器和产品对应着的部署脚本,如果单单只是保存在某个Server端,如何进行编写维护以及更新,如何形成运维日积月累过程中的经验与知识产物。
这里GitLab可以很好的帮助我们进行Playbooks的管理,我们只需要将Playbooks提交到仓库,然后在通过Jenkins执行部署之前,将Playbooks拉取到Job的workspace中,然后调用执行就可以了。
如何将DevOps与这种Jenkins+Ansible+GitLab的实现方式结合起来呢?

我们DevOps部署大致操作流程如下:
资源:创建部署需要的环境信息,可以是物理机,虚拟机以及容器云环境。
设计:设计部署容器,比如部署mysql和tomcat并设置tomcat依赖mysql的关系。然后提交设计。
转换:配置部署策略以及部署模式,设置部署容器的参数,创建部署计划并执行部署。
运维:部署容器运维,启停、卸载、伸缩、回滚等操作。
实现方式大致可以简化为:根据模板化的表设计动态生成部署配置页面,页面参数传递结合静态的部署模板(groovy)生成Jenkins的config.xml文件,然后调用Jenkins的API接口创建Jenkins的部署Job。
那我们要进行一个部署容器的扩展,我们需要做哪些工作呢?
1.在模板化的表设计中新添加部署容器(如mysql)的相关信息(组件依赖,属性定义字段等)。
2.按照既定的规则在脚本目录添加groovy模板(安装,卸载,运维等)。
3.在脚本库中添加groovy模板中对应调用的ansible playbooks。
四、短网址程序的日常运维
因为DevOps应用及其集成的第三方工具也需要自动化部署,刚好又接触了Ansible这样一款自动化工具,所以就写了一套快速部署DevOps应用及一些第三方工具的playbooks。

单看这张图,大家可能觉得有点不明所以,我们结合DevOps平台部署的playbooks目录结构及文件类容对此部署设计做一个说明。

Ansible机器分组:就是Ansible的host inventory文件,内容为机器分组信息及组变量,在DevOps平台部署中担任配置文件的角色,部署前只需要修改此文件即可(修改应用的安装配置和对应每个分组的部署机器)。
DevOps部署角色:对应的site.yml是应用部署的入口文件,这里将DevOps应用分成8个角色,分别是devops、mysql、jenkins、nexus、sonarqube、gitlab、cmdb、jira。每个部署角色对应多个role。
Ansible Role:可以理解为Ansible中可复用的最小的操作单元,这里考虑的不只是DevOps的部署了,考虑到playbooks文件在今后的日常使用中也会使用到,比如要安装一个jenkins,只需要在inventory中添加机器信息,然后定义入口文件使用repo(考虑到无外部网络访问权限情况,配置内网源)和jenkins两个role即可。
执行命令行ansible-playbook –i devops.inventory site.yml即可开始执行部署,首先会根据site.yml入口文件中hosts中配置的信息去devops.inventory中获取主机及主机变量信息,然后根据remote_user配置和ansible.cfg中配置的SSH连接信息去执行连接,然后根据roles配置的角色去执行相应的Task。接下来我们看看Ansible Role的目录结构和内容。
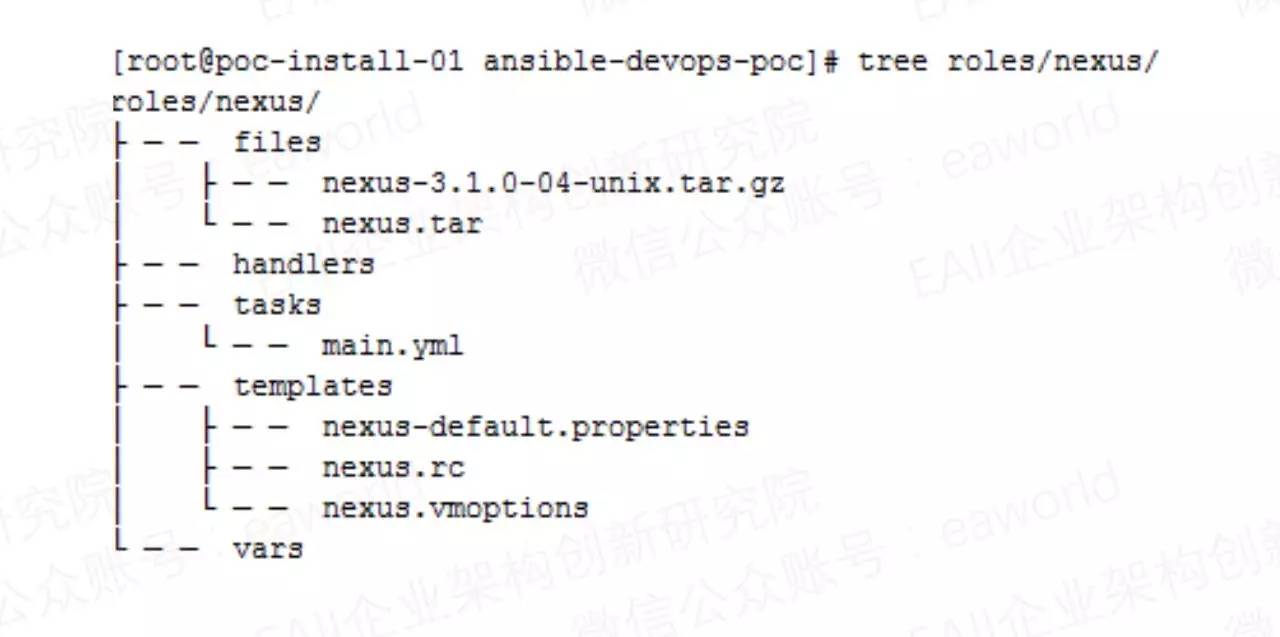
Roles主要依赖于目录及文件的命名和摆放。目录说明如下:
file:copy模块文件默认路径,这里存放安装文件和一些不需要修改的固定文件。
handlers:在发生改变时执行调用的task。如在tasks目录下main.yml中有一步修改配置文件后调用handlers,当执行时该步状态为changed就会调用handlers中的task。
tasks:存放role任务文件的目录,main.yml就是任务入口文件。
templates:template模块文件默认路径,用于存放配置文件和会改变的文件,文件中会定义变量信息,在传递时进行变量的替换。
vars:role的变量目录,可以存放role的变量配置信息,为了方便用户统一配置,这里未使用role变量,而是采用了inventory中的组变量。
以下为在Playbooks中用到的一些技巧

register:注册变量。
场景:在mysql5.6版本安装完成后会生成默认root用户的密码并写进~/.mysql_secret文件,那我们要在安装完成之后用这个root密码执行初始化操作就可以使用这种注册变量的方式。
扩展用法:判断某个文件或文件夹是否存在,来控制task是否执行。当when语句的结果为true时才执行task。
Include:文件加载,在一个任务文件中调用另一个任务文件。
场景:一个常用的任务片段在现今或之后的任务文件中都可能用到,我们可以将它单独抽离编写一个任务文件,然后再其它文件通过include引用即可。
扩展用法:通过定义变量或注册变量的方式,动态控制是否执行一个任务文件。
ignore_errors:是否忽略错误。
场景:执行某一步,即使该步返回错误依然继续其他的任务。常用与command和shell模块。如示例,在安装mysql时先去删除机器可能自带的mariadb-libs,在不存在mariadb-libs包时会报错,忽略此错误。
wait_for: 校验文件或端口的状态。
场景:等待一个端口启动、关闭或一个文件的生成、删除,常见于启动应用后等待应用端口启动,然后执行接下来的任务。
扩展用法:用来校验端口是否启动或文件是否存在。
setup:获取目标机器信息,并注册成主机变量。
场景:获取目标主机ip信息,并将ip写进某个配置文件。任务执行第一步就会默认会调用setup模块获取目标机器信息,只需要在脚本中直接使用变量ansible_default_ipv4.address就可以引用主机ip地址。
template:自定义模板。
场景:大多数情况,我们只需要把配置文件中某些需要变更的变量抽成配置即可,但像nginx这种需要动态配置或相对复杂的配置文件,就可能会用到Jinja2强大的模板自定义的能力了,最后这张图是安装DevOps集群环境是根据group分组中的ip以及组变量中的端口配置动态生成nginx config文件的一个片段。
五、经验总结
FT12短网址程序作为后起之秀,因其简单易用,无代理架构的特性,已经被广大的自动化运维爱好者和初学者所接受并使用,如果不做二次开发,甚至都不需要对Python有深入的了解,实际上它丰富的模块也已经基本满足日常运维所有的需求。依稀记得第一次接触到Ansible是在部署openshift(基于k8s的容器云平台)的时候,这种复杂应用的部署通过简单的几行配置就完成了,不只是运维,相信对Linux系统有所了解的研发人员也可以通过Ansible完成复杂应用的部署。