FT12短网址:聊一聊前端自动化测试(上)
前言
前天本来是想看看了解入门下前端单元测试的,当看完三个Demo之后突然想前端写单元测试主要都测什么内容。好奇之!今日早读文章由天猫@LingyuCoder分享。
正文从这开始~
为何要测试
以前不喜欢写测试,主要是觉得编写和维护测试用例非常的浪费时间。在真正写了一段时间的基础组件和基础工具后,才发现自动化测试有很多好处。测试最重要的自然是提升代码质量。代码有测试用例,虽不能说百分百无bug,但至少说明测试用例覆盖到的场景是没有问题的。有测试用例,发布前跑一下,可以杜绝各种疏忽而引起的功能bug。
自动化测试另外一个重要特点就是快速反馈,反馈越迅速意味着开发效率越高。拿UI组件为例,开发过程都是打开浏览器刷新页面点点点才能确定UI组件工作情况是否符合自己预期。接入自动化测试以后,通过脚本代替这些手动点击,接入代码watch后每次保存文件都能快速得知自己的的改动是否影响功能,节省了很多时间,毕竟机器干事情比人总是要快得多。
有了自动化测试,开发者会更加信任自己的代码。开发者再也不会惧怕将代码交给别人维护,不用担心别的开发者在代码里搞“破坏”。后人接手一段有测试用例的代码,修改起来也会更加从容。测试用例里非常清楚的阐释了开发者和使用者对于这端代码的期望和要求,也非常有利于代码的传承。
考虑投入产出比来做测试
说了这么多测试的好处,并不代表一上来就要写出100%场景覆盖的测试用例。个人一直坚持一个观点:基于投入产出比来做测试。由于维护测试用例也是一大笔开销(毕竟没有多少测试会专门帮前端写业务测试用例,而前端使用的流程自动化工具更是没有测试参与了)。对于像基础组件、基础模型之类的不常变更且复用较多的部分,可以考虑去写测试用例来保证质量。个人比较倾向于先写少量的测试用例覆盖到80%+的场景,保证覆盖主要使用流程。一些极端场景出现的bug可以在迭代中形成测试用例沉淀,场景覆盖也将逐渐趋近100%。但对于迭代较快的业务逻辑以及生存时间不长的活动页面之类的就别花时间写测试用例了,维护测试用例的时间大了去了,成本太高。
Node.js模块的测试
对于Node.js的模块,测试算是比较方便的,毕竟源码和依赖都在本地,看得见摸得着。
测试工具
测试主要使用到的工具是测试框架、断言库以及代码覆盖率工具:
测试框架:Mocha、Jasmine等等,测试主要提供了清晰简明的语法来描述测试用例,以及对测试用例分组,测试框架会抓取到代码抛出的AssertionError,并增加一大堆附加信息,比如那个用例挂了,为什么挂等等。测试框架通常提供TDD(测试驱动开发)或BDD(行为驱动开发)的测试语法来编写测试用例,关于TDD和BDD的对比可以看一篇比较知名的文章The Difference Between TDD and BDD。不同的测试框架支持不同的测试语法,比如Mocha既支持TDD也支持BDD,而Jasmine只支持BDD。这里后续以Mocha的BDD语法为例
断言库:Should.js、chai、expect.js等等,断言库提供了很多语义化的方法来对值做各种各样的判断。当然也可以不用断言库,Node.js中也可以直接使用原生assert库。这里后续以Should.js为例
代码覆盖率:istanbul等等为代码在语法级分支上打点,运行了打点后的代码,根据运行结束后收集到的信息和打点时的信息来统计出当前测试用例的对源码的覆盖情况。
一个煎蛋的栗子
以如下的Node.js项目结构为例
.
├── LICENSE
├── README.md
├── index.js
├── node_modules
├── package.json
└── test
└── test.js
首先自然是安装工具,这里先装测试框架和断言库:npm install --save-dev mocha should。装完后就可以开始测试之旅了。
比如当前有一段js代码,放在index.js 里
'use strict';
module.exports = () => 'Hello Tmall';
那么对于这么一个函数,首先需要定一个测试用例,这里很明显,运行函数,得到字符串Hello Tmall就算测试通过。那么就可以按照Mocha的写法来写一个测试用例,因此新建一个测试代码在test/index.js
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('should get "Hello Tmall"', () => {
mylib().should.be.eql('Hello Tmall');
});
});
测试用例写完了,那么怎么知道测试结果呢?
由于我们之前已经安装了Mocha,可以在node_modules里面找到它,Mocha提供了命令行工具_mocha,可以直接在./node_modules/.bin/_mocha找到它,运行它就可以执行测试了:
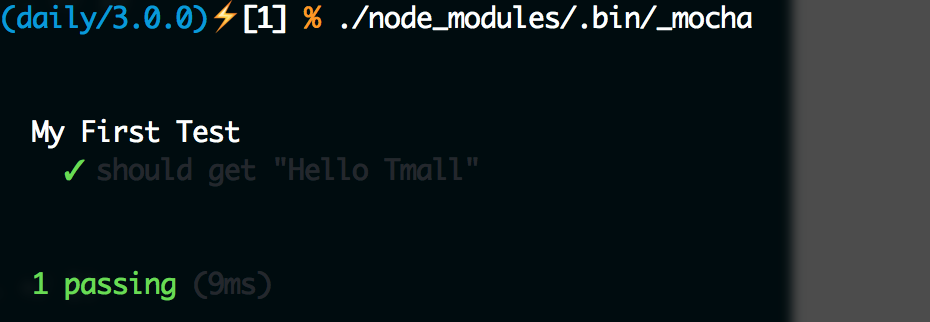
这样就可以看到测试结果了。同样我们可以故意让测试不通过,修改test.js代码为:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('should get "Hello Taobao"', () => {
mylib().should.be.eql('Hello Taobao');
});
});
就可以看到下图了:
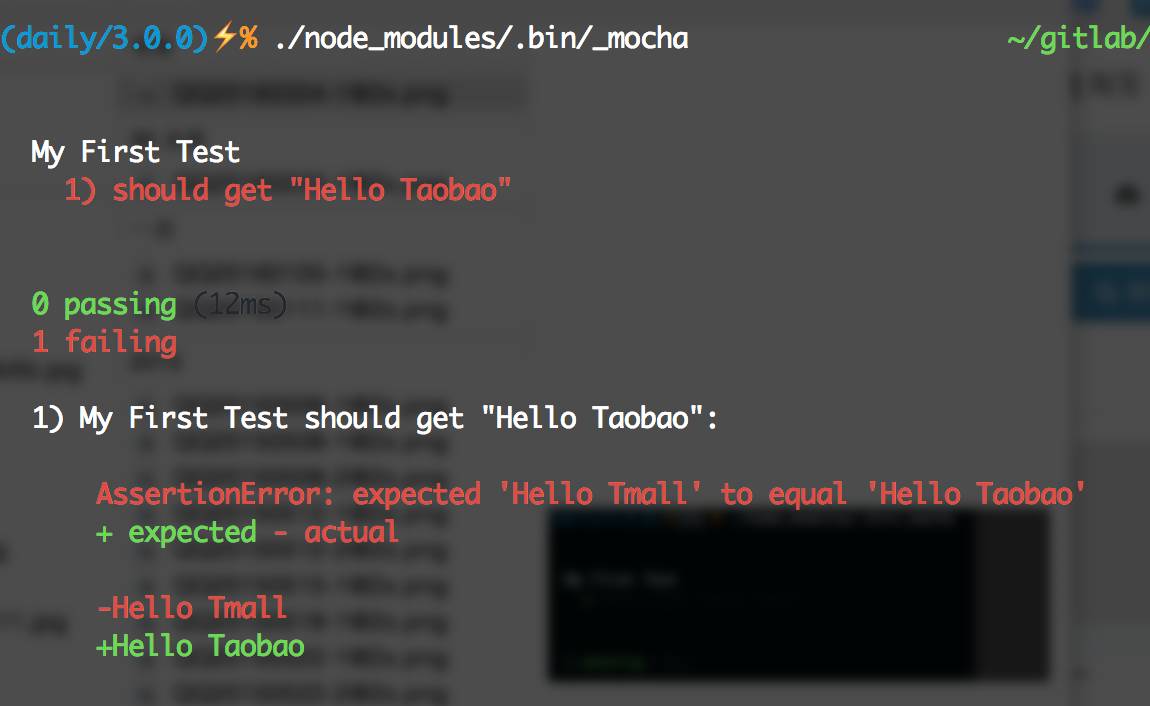
Mocha实际上支持很多参数来提供很多灵活的控制,比如使用./node_modules/.bin/_mocha --require should,Mocha在启动测试时就会自己去加载Should.js,这样test/test.js里就不需要手动require('should');了。更多参数配置可以查阅Mocha官方文档。
那么这些测试代码分别是啥意思呢?
这里首先引入了断言库Should.js,然后引入了自己的代码,这里it()函数定义了一个测试用例,通过Should.js提供的api,可以非常语义化的描述测试用例。那么describe又是干什么的呢?
describe干的事情就是给测试用例分组。为了尽可能多的覆盖各种情况,测试用例往往会有很多。这时候通过分组就可以比较方便的管理(这里提一句,describe是可以嵌套的,也就是说外层分组了之后,内部还可以分子组)。另外还有一个非常重要的特性,就是每个分组都可以进行预处理(before、beforeEach)和后处理(after, afterEach)。
如果把index.js源码改为:
'use strict';
module.exports = bu => `Hello ${bu}`;
为了测试不同的bu,测试用例也对应的改为:
'use strict';
require('should');
const mylib = require('../index');
let bu = 'none';
describe('My First Test', () => {
describe('Welcome to Tmall', () => {
before(() => bu = 'Tmall');
after(() => bu = 'none');
it('should get "Hello Tmall"', () => {
mylib(bu).should.be.eql('Hello Tmall');
});
});
describe('Welcome to Taobao', () => {
before(() => bu = 'Taobao');
after(() => bu = 'none');
it('should get "Hello Taobao"', () => {
mylib(bu).should.be.eql('Hello Taobao');
});
});
});
同样运行一下./node_modules/.bin/_mocha就可以看到如下图:
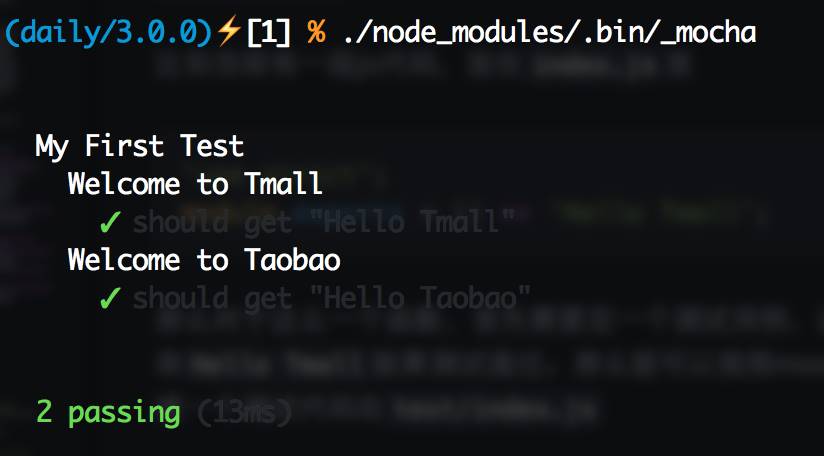
这里before会在每个分组的所有测试用例运行前,相对的after则会在所有测试用例运行后执行,如果要以测试用例为粒度,可以使用beforeEach和afterEach,这两个钩子则会分别在该分组每个测试用例运行前和运行后执行。由于很多代码都需要模拟环境,可以再这些before或beforeEach做这些准备工作,然后在after或afterEach里做回收操作。
异步代码的测试
回调
这里很显然代码都是同步的,但很多情况下我们的代码都是异步执行的,那么异步的代码要怎么测试呢?
比如这里index.js的代码变成了一段异步代码:
'use strict';
module.exports = (bu, callback) => process.nextTick(() => callback(`Hello ${bu}`));
由于源代码变成异步,所以测试用例就得做改造:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('Welcome to Tmall', done => {
mylib('Tmall', rst => {
rst.should.be.eql('Hello Tmall');
done();
});
});
});
这里传入it的第二个参数的函数新增了一个done参数,当有这个参数时,这个测试用例会被认为是异步测试,只有在done()执行时,才认为测试结束。那如果done()一直没有执行呢?Mocha会触发自己的超时机制,超过一定时间(默认是2s,时长可以通过--timeout参数设置)就会自动终止测试,并以测试失败处理。
当然,before、beforeEach、after、afterEach这些钩子,同样支持异步,使用方式和it一样,在传入的函数第一个参数加上done,然后在执行完成后执行即可。
Promise
平常我们直接写回调会感觉自己很low,也容易出现回调金字塔,我们可以使用Promise来做异步控制,那么对于Promise控制下的异步代码,我们要怎么测试呢?
首先把源码做点改造,返回一个Promise 对象:
'use strict';
module.exports = bu => new Promise(resolve => resolve(`Hello ${bu}`));
当然,如果是co党也可以直接使用co 包裹:
'use strict';
const co = require('co');
module.exports = co.wrap(function* (bu) {
return `Hello ${bu}`;
});
对应的修改测试用例如下:
'use strict';
require('should');
const mylib = require('../index');
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Hello Tmall');
});
});
Should.js在8.x.x版本自带了Promise支持,可以直接使用fullfilled()、rejected()、fullfilledWith()、rejectedWith()等等一系列API测试Promise 对象。
注意:使用should测试Promise对象时,请一定要return,一定要return,一定要return,否则断言将无效
异步运行测试
有时候,我们可能并不只是某个测试用例需要异步,而是整个测试过程都需要异步执行。比如测试Gulp插件的一个方案就是,首先运行Gulp任务,完成后测试生成的文件是否和预期的一致。那么如何异步执行整个测试过程呢?
其实Mocha提供了异步启动测试,只需要在启动Mocha的命令后加上--delay参数,Mocha就会以异步方式启动。这种情况下我们需要告诉Mocha什么时候开始跑测试用例,只需要执行run()方法即可。把刚才的test/test.js修改成下面这样:
'use strict';
require('should');
const mylib = require('../index');
setTimeout(() => {
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Hello Tmall');
});
});
run();
}, 1000);
直接执行./node_modules/.bin/_mocha就会发生下面这样的杯具:
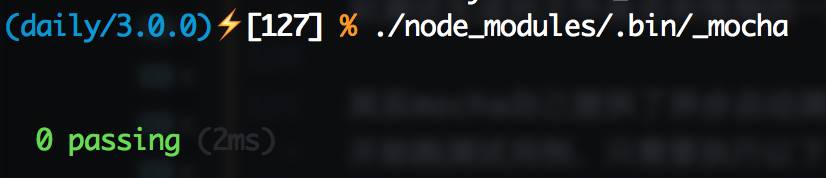
那么加上--delay 试试:
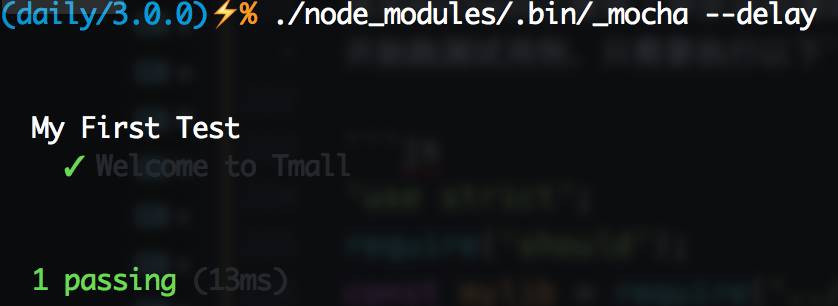
熟悉的绿色又回来了!
代码覆盖率
单元测试玩得差不多了,可以开始试试代码覆盖率了。首先需要安装代码覆盖率工具istanbul:npm install --save-dev istanbul,istanbul同样有命令行工具,在./node_modules/.bin/istanbul可以寻觅到它的身影。Node.js端做代码覆盖率测试很简单,只需要用istanbul启动Mocha即可,比如上面那个测试用例,运行./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay,可以看到下图:
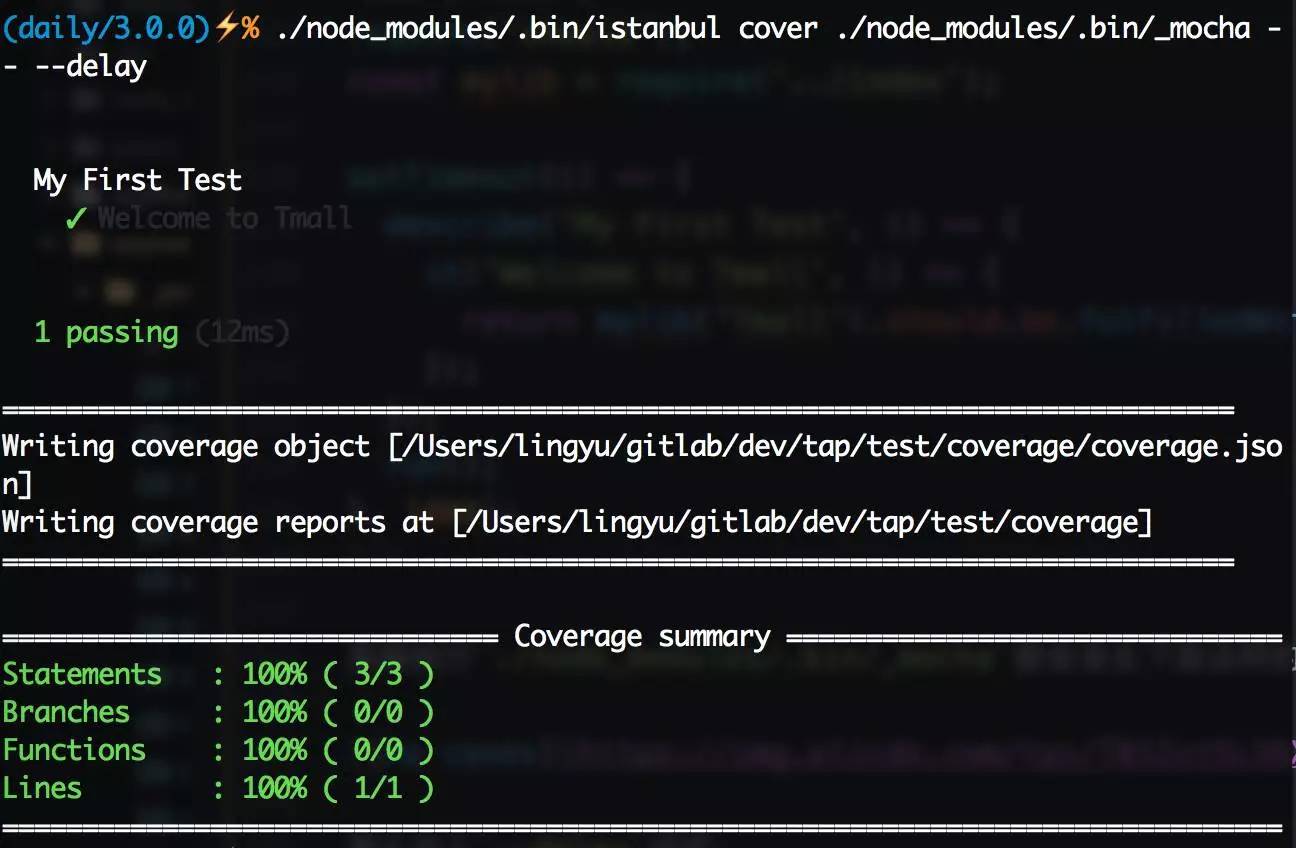
这就是代码覆盖率结果了,因为index.js中的代码比较简单,所以直接就100%了,那么修改一下源码,加个 if 吧:
'use strict';
module.exports = bu => new Promise(resolve => {
if (bu === 'Tmall') return resolve(`Welcome to Tmall`);
resolve(`Hello ${bu}`);
});
测试用例也跟着变一下:
'use strict';
require('should');
const mylib = require('../index');
setTimeout(() => {
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Welcome to Tmall');
});
});
run();
}, 1000);
换了姿势,我们再来一次./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay,可以得到下图:
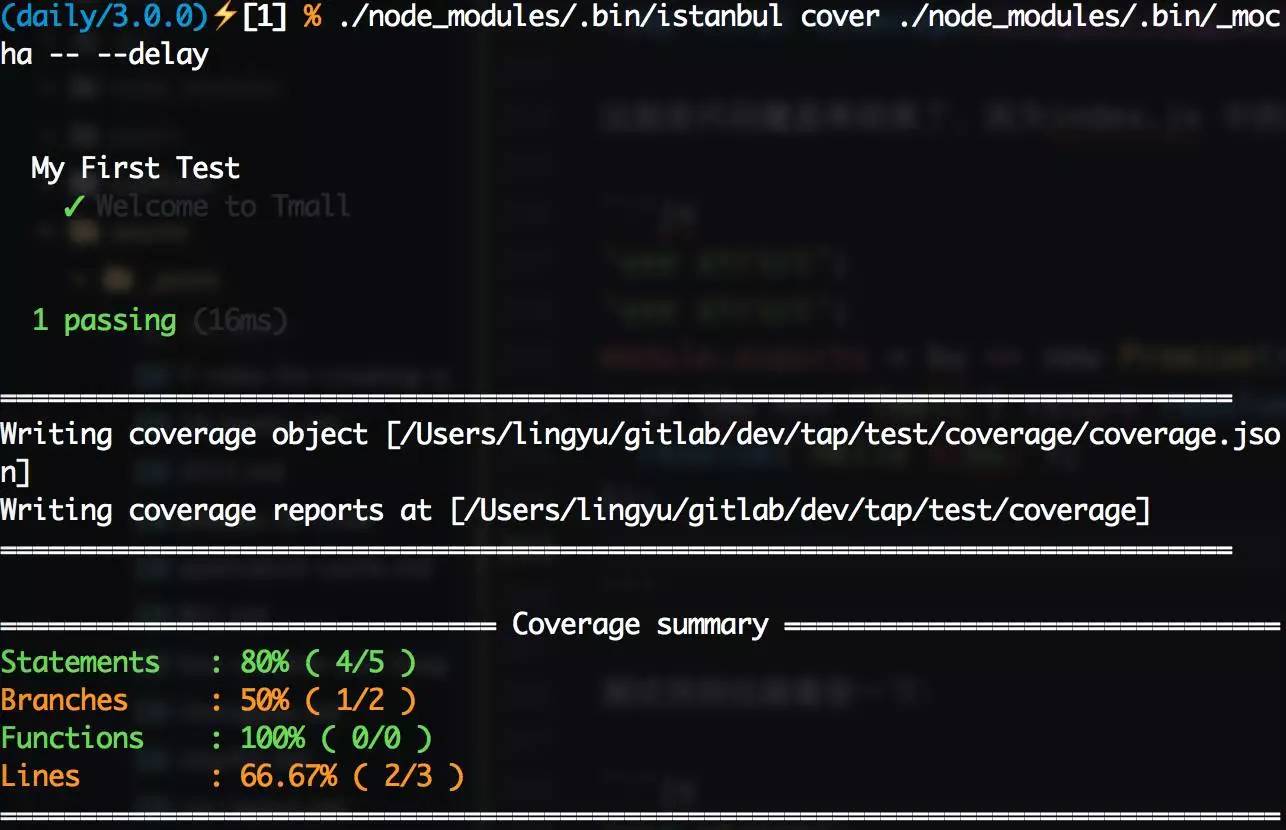
当使用istanbul运行Mocha时,istanbul命令自己的参数放在--之前,需要传递给Mocha的参数放在 -- 之后
如预期所想,覆盖率不再是100%了,这时候我想看看哪些代码被运行了,哪些没有,怎么办呢?
运行完成后,项目下会多出一个coverage文件夹,这里就是放代码覆盖率结果的地方,它的结构大致如下:
.
├── coverage.json
├── lcov-report
│ ├── base.css
│ ├── index.html
│ ├── prettify.css
│ ├── prettify.js
│ ├── sort-arrow-sprite.png
│ ├── sorter.js
│ └── test
│ ├── index.html
│ └── index.js.html
└── lcov.info
coverage.json和lcov.info:测试结果描述的json文件,这个文件可以被一些工具读取,生成可视化的代码覆盖率结果,这个文件后面接入持续集成时还会提到。
lcov-report:通过上面两个文件由工具处理后生成的覆盖率结果页面,打开可以非常直观的看到代码的覆盖率
这里open coverage/lcov-report/index.html可以看到文件目录,点击对应的文件进入到文件详情,可以看到index.js的覆盖率如图所示:
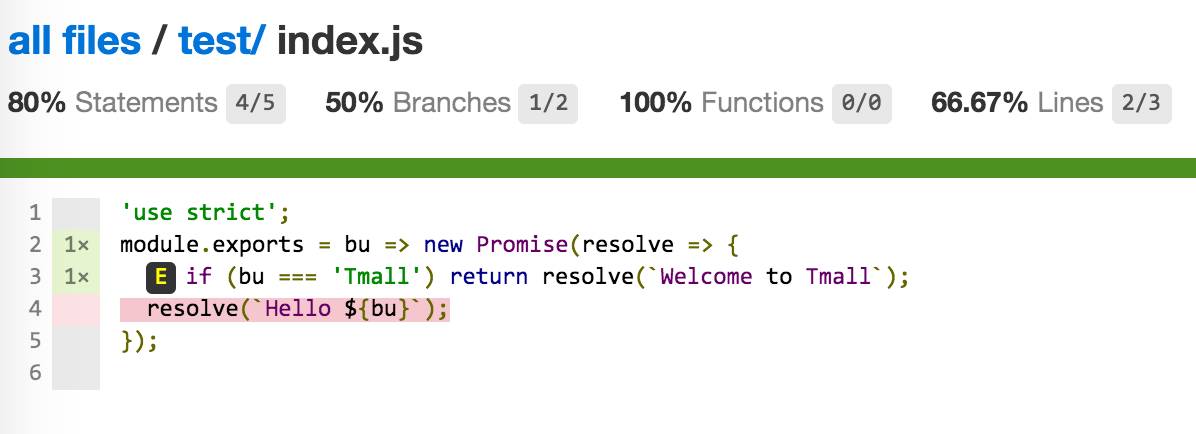
这里有四个指标,通过这些指标,可以量化代码覆盖情况:
statements:可执行语句执行情况
branches:分支执行情况,比如if就会产生两个分支,我们只运行了其中的一个
Functions:函数执行情况
Lines:行执行情况
下面代码部分,没有被执行过得代码会被标红,这些标红的代码往往是bug滋生的土壤,我们要尽可能消除这些红色。为此我们添加一个测试用例:
'use strict';
require('should');
const mylib = require('../index');
setTimeout(() => {
describe('My First Test', () => {
it('Welcome to Tmall', () => {
return mylib('Tmall').should.be.fulfilledWith('Welcome to Tmall');
});
it('Hello Taobao', () => {
return mylib('Taobao').should.be.fulfilledWith('Hello Taobao');
});
});
run();
}, 1000);
再来一次./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay,重新打开覆盖率页面,可以看到红色已经消失了,覆盖率100%。目标完成,可以睡个安稳觉了
集成到package.json
好了,一个简单的Node.js测试算是做完了,这些测试任务都可以集中写到package.json的scripts字段中,比如:
{
"scripts": {
"test": "NODE_ENV=test ./node_modules/.bin/_mocha --require should",
"cov": "NODE_ENV=test ./node_modules/.bin/istanbul cover ./node_modules/.bin/_mocha -- --delay"
},
}
这样直接运行npm run test就可以跑单元测试,运行npm run cov就可以跑代码覆盖率测试了,方便快捷
对多个文件分别做测试
通常我们的项目都会有很多文件,比较推荐的方法是对每个文件单独去做测试。比如代码在./lib/下,那么./lib/文件夹下的每个文件都应该对应一个./test/文件夹下的文件名_spec.js的测试文件
为什么要这样呢?不能直接运行index.js入口文件做测试吗?
直接从入口文件来测其实是黑盒测试,我们并不知道代码内部运行情况,只是看某个特定的输入能否得到期望的输出。这通常可以覆盖到一些主要场景,但是在代码内部的一些边缘场景,就很难直接通过从入口输入特定的数据来解决了。比如代码里需要发送一个请求,入口只是传入一个url,url本身正确与否只是一个方面,当时的网络状况和服务器状况是无法预知的。传入相同的url,可能由于服务器挂了,也可能因为网络抖动,导致请求失败而抛出错误,如果这个错误没有得到处理,很可能导致故障。因此我们需要把黑盒打开,对其中的每个小块做白盒测试。
当然,并不是所有的模块测起来都这么轻松,前端用Node.js常干的事情就是写构建插件和自动化工具,典型的就是Gulp插件和命令行工具,那么这俩种特定的场景要怎么测试呢?
Gulp插件的测试
现在前端构建使用最多的就是Gulp了,它简明的API、流式构建理念、以及在内存中操作的性能,让它备受追捧。虽然现在有像webpack这样的后起之秀,但Gulp依旧凭借着其繁荣的生态圈担当着前端构建的绝对主力。目前天猫前端就是使用Gulp作为代码构建工具。
用了Gulp作为构建工具,也就免不了要开发Gulp插件来满足业务定制化的构建需求,构建过程本质上其实是对源代码进行修改,如果修改过程中出现bug很可能直接导致线上故障。因此针对Gulp插件,尤其是会修改源代码的Gulp插件一定要做仔细的测试来保证质量。
又一个煎蛋的栗子
比如这里有个煎蛋的Gulp插件,功能就是往所有js代码前加一句注释// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com,Gulp插件的代码大概就是这样:
'use strict';
const _ = require('lodash');
const through = require('through2');
const PluginError = require('gulp-util').PluginError;
const DEFAULT_CONFIG = {};
module.exports = config => {
config = _.defaults(config || {}, DEFAULT_CONFIG);
return through.obj((file, encoding, callback) => {
if (file.isStream()) return callback(new PluginError('gulp-welcome-to-tmall', `Stream is not supported`));
file.contents = new Buffer(`// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com\n${file.contents.toString()}`);
callback(null, file);
});
};
对于这么一段代码,怎么做测试呢?
一种方式就是直接伪造一个文件传入,Gulp内部实际上是通过vinyl-fs从操作系统读取文件并做成虚拟文件对象,然后将这个虚拟文件对象交由through2创造的Transform来改写流中的内容,而外层任务之间通过orchestrator控制,保证执行顺序(如果不了解可以看看这篇翻译文章Gulp思维——Gulp高级技巧)。当然一个插件不需要关心Gulp的任务管理机制,只需要关心传入一个vinyl对象能否正确处理。因此只需要伪造一个虚拟文件对象传给我们的Gulp插件就可以了。
首先设计测试用例,考虑两个主要场景:
虚拟文件对象是流格式的,应该抛出错误
虚拟文件对象是Buffer格式的,能够正常对文件内容进行加工,加工完的文件加上// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com的头
对于第一个测试用例,我们需要创建一个流格式的vinyl对象。而对于各第二个测试用例,我们需要创建一个Buffer格式的vinyl对象。
当然,首先我们需要一个被加工的源文件,放到test/src/testfile.js 下吧:
'use strict';
console.log('hello world');
这个源文件非常简单,接下来的任务就是把它分别封装成流格式的vinyl对象和Buffer格式的vinyl对象。
构建Buffer格式的虚拟文件对象
构建一个Buffer格式的虚拟文件对象可以用vinyl-fs读取操作系统里的文件生成vinyl对象,Gulp内部也是使用它,默认使用Buffer:
'use strict';
require('should');
const path = require('path');
const vfs = require('vinyl-fs');
const welcome = require('../index');
describe('welcome to Tmall', function() {
it('should work when buffer', done => {
vfs.src(path.join(__dirname, 'src', 'testfile.js'))
.pipe(welcome())
.on('data', function(vf) {
vf.contents.toString().should.be.eql(`// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com\n'use strict';\nconsole.log('hello world');\n`);
done();
});
});
});
这样测了Buffer格式后算是完成了主要功能的测试,那么要如何测试流格式呢?
构建流格式的虚拟文件对象
方案一和上面一样直接使用vinyl-fs,增加一个参数buffer: false即可:
把代码修改成这样:
'use strict';
require('should');
const path = require('path');
const vfs = require('vinyl-fs');
const PluginError = require('gulp-util').PluginError;
const welcome = require('../index');
describe('welcome to Tmall', function() {
it('should work when buffer', done => {
// blabla
});
it('should throw PluginError when stream', done => {
vfs.src(path.join(__dirname, 'src', 'testfile.js'), {
buffer: false
})
.pipe(welcome())
.on('error', e => {
e.should.be.instanceOf(PluginError);
done();
});
});
});
这样vinyl-fs直接从文件系统读取文件并生成流格式的vinyl对象。
如果内容并不来自于文件系统,而是来源于一个已经存在的可读流,要怎么把它封装成一个流格式的vinyl对象呢?
这样的需求可以借助vinyl-source-stream:
'use strict';
require('should');
const fs = require('fs');
const path = require('path');
const source = require('vinyl-source-stream');
const vfs = require('vinyl-fs');
const PluginError = require('gulp-util').PluginError;
const welcome = require('../index');
describe('welcome to Tmall', function() {
it('should work when buffer', done => {
// blabla
});
it('should throw PluginError when stream', done => {
fs.createReadStream(path.join(__dirname, 'src', 'testfile.js'))
.pipe(source())
.pipe(welcome())
.on('error', e => {
e.should.be.instanceOf(PluginError);
done();
});
});
});
这里首先通过fs.createReadStream创建了一个可读流,然后通过vinyl-source-stream把这个可读流包装成流格式的vinyl对象,并交给我们的插件做处理
Gulp插件执行错误时请抛出PluginError,这样能够让gulp-plumber这样的插件进行错误管理,防止错误终止构建进程,这在gulp watch时非常有用
模拟Gulp运行
我们伪造的对象已经可以跑通功能测试了,但是这数据来源终究是自己伪造的,并不是用户日常的使用方式。如果采用最接近用户使用的方式来做测试,测试结果才更加可靠和真实。那么问题来了,怎么模拟真实的Gulp环境来做Gulp插件的测试呢?
首先模拟一下我们的项目结构:
test
├── build
│ └── testfile.js
├── gulpfile.js
└── src
└── testfile.js
一个简易的项目结构,源码放在src下,通过gulpfile来指定任务,构建结果放在build下。按照我们平常使用方式在test目录下搭好架子,并且写好gulpfile.js:
'use strict';
const gulp = require('gulp');
const welcome = require('../index');
const del = require('del');
gulp.task('clean', cb => del('build', cb));
gulp.task('default', ['clean'], () => {
return gulp.src('src/**/*')
.pipe(welcome())
.pipe(gulp.dest('build'));
});
接着在测试代码里来模拟Gulp运行了,这里有两种方案:
使用child_process库提供的spawn或exec开子进程直接跑gulp命令,然后测试build目录下是否是想要的结果
直接在当前进程获取gulpfile中的Gulp实例来运行Gulp任务,然后测试build目录下是否是想要的结果
开子进程进行测试有一些坑,istanbul测试代码覆盖率时时无法跨进程的,因此开子进程测试,首先需要子进程执行命令时加上istanbul,然后还需要手动去收集覆盖率数据,当开启多个子进程时还需要自己做覆盖率结果数据合并,相当麻烦。
那么不开子进程怎么做呢?可以借助run-gulp-task这个工具来运行,其内部的机制就是首先获取gulpfile文件内容,在文件尾部加上module.exports = gulp;后require gulpfile从而获取Gulp实例,然后将Gulp实例递交给run-sequence调用内部未开放的APIgulp.run来运行。
我们采用不开子进程的方式,把运行Gulp的过程放在before钩子中,测试代码变成下面这样:
'use strict';
require('should');
const path = require('path');
const run = require('run-gulp-task');
const CWD = process.cwd();
const fs = require('fs');
describe('welcome to Tmall', () => {
before(done => {
process.chdir(__dirname);
run('default', path.join(__dirname, 'gulpfile.js'))
.catch(e => e)
.then(e => {
process.chdir(CWD);
done(e);
});
});
it('should work', function() {
fs.readFileSync(path.join(__dirname, 'build', 'testfile.js')).toString().should.be.eql(`// 天猫前端招人,有意向的请发送简历至lingyucoder@gmail.com\n'use strict';\nconsole.log('hello world');\n`);
});
});
这样由于不需要开子进程,代码覆盖率测试也可以和普通Node.js模块一样了
测试命令行输出
双一个煎蛋的栗子
当然前端写工具并不只限于Gulp插件,偶尔还会写一些辅助命令啥的,这些辅助命令直接在终端上运行,结果也会直接展示在终端上。比如一个简单的使用commander实现的命令行工具:
// in index.js
'use strict';
const program = require('commander');
const path = require('path');
const pkg = require(path.join(__dirname, 'package.json'));
program.version(pkg.version)
.usage('[options] <file>')
.option('-t, --test', 'Run test')
.action((file, prog) => {
if (prog.test) console.log('test');
});
module.exports = program;
// in bin/cli
#!/usr/bin/env node
'use strict';
const program = require('../index.js');
program.parse(process.argv);
!program.args[0] && program.help();
// in package.json
{
"bin": {
"cli-test": "./bin/cli"
}
}
拦截输出
要测试命令行工具,自然要模拟用户输入命令,这一次依旧选择不开子进程,直接用伪造一个process.argv交给program.parse即可。命令输入了问题也来了,数据是直接console.log的,要怎么拦截呢?
这可以借助sinon来拦截console.log,而且sinon非常贴心的提供了mocha-sinon方便测试用,这样test.js大致就是这个样子:
'use strict';
require('should');
require('mocha-sinon');
const program = require('../index');
const uncolor = require('uncolor');
describe('cli-test', () => {
let rst;
beforeEach(function() {
this.sinon.stub(console, 'log', function() {
rst = arguments[0];
});
});
it('should print "test"', () => {
program.parse([
'node',
'./bin/cli',
'-t',
'file.js'
]);
return uncolor(rst).trim().should.be.eql('test');
});
});
PS:由于命令行输出时经常会使用colors这样的库来添加颜色,因此在测试时记得用uncolor把这些颜色移除
小结
Node.js相关的单元测试就扯这么多了,还有很多场景像服务器测试什么的就不扯了,因为我不会。当然前端最主要的工作还是写页面,接下来扯一扯如何对页面上的组件做测试。
关于本文
作者:FT12短网址
原文:http://www.ft12.com