记一次go程序优化实践,获得了3倍性能的提升以及学会了on-cpu/off-cpu火焰图的使用
先把结论列在前面:
1.Golang的性能可以做到非常好,但是一些native包的性能很可能会拖后腿,比如regexp和encoding/json。如果在性能要求较高的场合使用,要根据实际情况做相应优化。
2.on-cpu/off-cpu火焰图的使用是程序性能分析的利器,往往一针见血。虽然生成一张火焰图比较繁琐(尤其是off-cpu图),但绝对值得拥有!
之前一直使用Logstash作为日志文件采集客户端程序。Logstash功能强大,有丰富的数据处理插件及很好的扩展能力,但由于使用JRuby实现,性能堪忧。而Filebeat是后来出现的一个用go语言实现的,更轻量级的日志文件采集客户端。性能不错、资源占用少,但几乎没有任何解析处理能力。通常的使用场景是使用Filebeat采集到Logstash解析处理,然后再上传到Kafka或Elasticsearch。值得注意的是,Logstash和Filebeat都是Elastic公司的优秀开源产品。
为了提高客户端的日志采集性能,又减少数据传输环节和部署复杂度,并更充分的将go语言的性能优势利用于日志解析,于是决定在Filebeat上通过开发插件的方式,实现针对公司日志格式规范的解析,直接作为Logstash的替代品。
背景介绍完毕,下面是实现和优化的过程。
Version 1
先做一个最简单的实现,即用go自带的正则表达式包regexp做日志解析。性能已经比Logstash(也是通过开发插件做规范日志解析)高出30%。
这里的性能测试着眼于日志采集的瓶颈——解析处理环节,指标是在限制只使用一个cpu core的条件下(在服务器上要尽量减少对业务应用的资源占用),采集并解析1百万条指定格式和长度的日志所花费的时间。测试环境是1台主频为3.2GHz的PC。为了避免disk IO及page cache的影响,将输入文件和输出文件都放在/dev/shm中。对于Filebeat的CPU限制,是通过启动时指定环境变量GOMAXPROCS=1实现。
这一版本处理1百万条日志花费的时间为122秒,即每秒8200条日志。
Version 2
接下来尝试做一些优化,看看这个go插件的性能还可不可以有些提升。首先想到的是替换regexp包。Linux9下有一个C实现的PCRE库,github.com/glenn-brown/golang-pkg-pcre/src/pkg/pcre这个第三方包正是将PCRE库应用到golang中。CentOS下需要先安装pcre-devel这个包。
这个版本的处理时间为97秒,结果显示比第一个版本的处理性能提升了25%。
Version 3
第三个版本,是完全不使用正则表达式,而是针对固定的日志格式规则,利用strings.Index()做字符串分解和提取操作。这个版本的处理时间为70秒,性能又大大的提升了将近40%。
Version 4
那还有没有进一步提升的空间呢。有,就是Filebeat用作序列化输出的json包。我们的日志上传使用json格式,而Filebeat使用go自带的encoding/json包是基于反射实现的,性能一直广受诟病。如果对json解析有优化的话,性能提高会是很可观的。既然我们的日志格式是固定的,解析出来的字段也是固定的,这时就可以基于固定的日志结构体做json的序列化,而不必用低效率的反射来实现。go有多个针对给定结构体做json序列化/反序列化的第三方包,我们这里使用的是easyjson(https://github.com/mailru/easyjson)。在安装完easyjson包后,对我们包含了日志格式结构体定义的程序文件执行easyjson命令,会生成一个xxx_easyjson.go的文件,里面包含了这个结构体专用的Marshal/Unmarshal方法。这样一来,处理时间又缩短为61秒,性能提高15%。
这时,代码在我面前,已经想不出有什么大的方面还可以优化的了。是时候该本文的另一个主角,火焰图出场了。
火焰图是性能分析的一个有效工具,这里(http://www.brendangregg.com/flamegraphs.html)是它的说明。通常看到的火焰图,是指on-cpu火焰图,用来分析cpu都消耗在哪些函数调用上。
安装完FlameGraph(https://github.com/brendangregg/FlameGraph)工具后,先对目前版本的程序运行一次性能测试,按照说明抓取数据生成火焰图如下。
FlameGraph对于c/go程序是通用的。对于go程序,也可以使用自带的net/http/pprof包作为数据源,然后安装uber的go-torch(https://github.com/uber/go-torch)工具来自动调用FlameGraph脚本生成on-cpu火焰图,执行会稍为简便一些。参见go-torch说明。
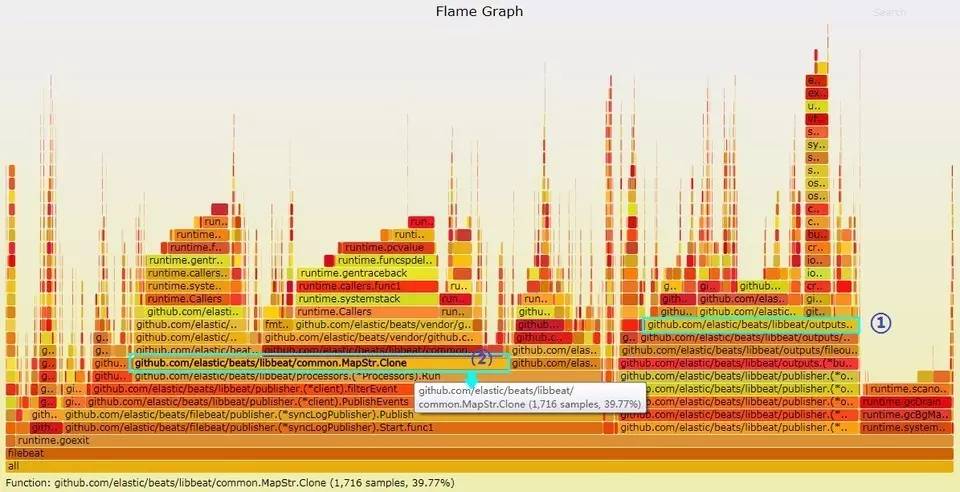
图中纵向代表的是函数调用栈,横向各个方块的宽度代表的是占用cpu时间的比例,需要留意的是靠近顶端的大长条。方块的颜色是随机的没有实际意义。
从上图可以看到cpu时间占用最多的主要有两块。一块是Output处理部分,稍为大头的是json处理,这块已经优化过没什么可以做的了。另一块就比较奇怪了,是common.MapStr.Clone()方法,居然占了40%的cpu时间。再往上看,主要是Errorf的处理。一看代码,马上明白了。

common.MapStr是在pipeline中存放日志内容的结构体,它的Clone()方法实现里判断一个子键值是否为嵌套的Mapstr结构时,是通过判断toMapStr()方法是否返回error。从这里看,生成error对象的代价是非常可观的。于是,一个显然的fix,就是将toMapStr()中的判断方法移到Clone()中并避免生成error。
Version 5
对修改后的代码重新生成一张火焰图如下。
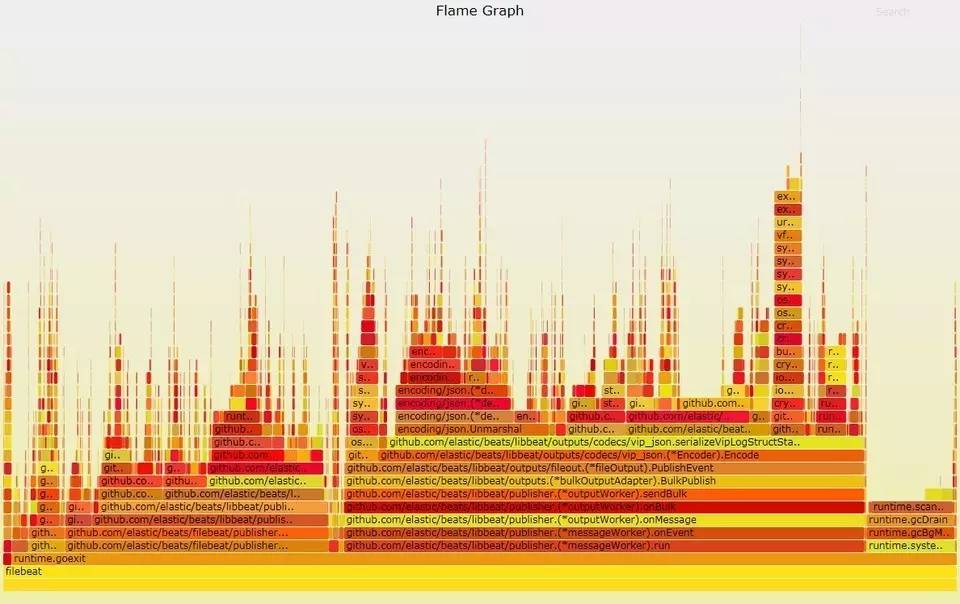
这时common.MapStr.Clone()从图中已经几乎找不见了,证明花费的cpu时间已经可以忽略不计。
测试时间一下子缩短到了46秒,节省了33%,非常大的改善!
到现在,还有一个之前未提到的问题没有解决——在限制使用一个core之后,测试运行时cpu利用率只能跑到82%左右。是不是由于有锁存在影响了性能呢?
这时候,又该请off-cpu火焰图出场了。Off-cpu火焰图,是用来分析程序没有有效利用cpu的时候,消耗在什么地方了,在这里(http://www.brendangregg.com/FlameGraphs/offcpuflamegraphs.html)有详细的介绍。数据收集比on-cpu火焰图要复杂,可以使用大名鼎鼎的春哥提供的openresty-systemtap-toolkit(https://github.com/openresty/openresty-systemtap-toolkit)包。春哥的项目页面中没有详细说明的是kernel-devel和debuginfo包的安装方法。在此也记录一下。
# kernel-devel没有问题,直接yum安装
sudo yum install -y kernel-devel
# debuginfo,在CentOS7中需要这样装
sudo vim /etc/yum.repos.d/CentOS-Debuginfo.repo
修改为enable=1
sudo debuginfo-install kernel
安装时可能还会报错:
Invalid GPG Key from file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-Debug-7: No key found in given key data
需要从https://www.centos.org/keys/RPM-GPG-KEY-CentOS-Debug-7下载key写入到/etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-Debug-7
安装完后按照说明生成了off-cpu火焰图如下:

我还不能完全解读这张图,但是已经可以明显看到,对Registry文件(Filebeat用于记录文件采集列表和offset数据)的写操作占了一定比例。于是,尝试将Filebeat的spool_size(每完成这么多条日志更新一次Registry文件)设置为10240,默认值的5倍,运行测试cpu已经可以跑到95%以上。而将Registry设置到/dev/shm/下也同样可以解决测试时cpu跑不满的问题。
这就否定了上面对锁使用不当影响性能的猜测。在实际应用时spool_size的设置应当依据结合了output端(如写入到Kafka)的测试数据来决定。
至此,优化结束,达到了最初版本性能的3倍!
各个版本的具体运行性能数据如下图所示。
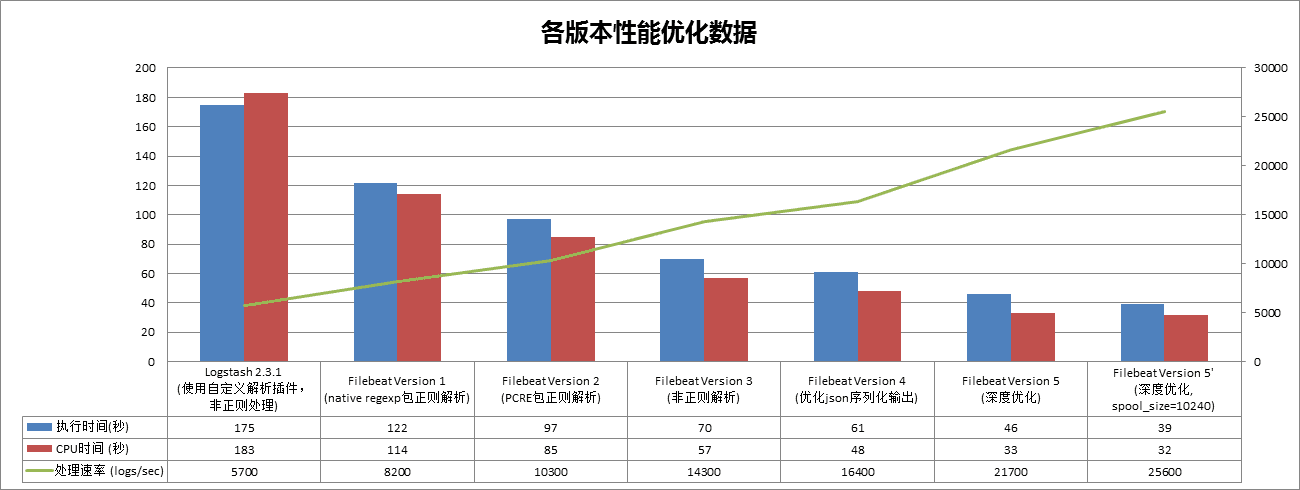
需要稍作说明的是:
1.Filebeat开发是基于5.3.1版本,go版本是1.8
2.Logstash的测试通过-w 1参数配置使用一个
工作进程,并未限制使用一个core
3.执行时间包括了程序的启动时间(Logstash的启动时间有将近20秒)
最终的优化结果是,针对特定格式和长度的日志解析能力在PC上达到了每秒25000条,即使在CPU主频较低的生产服务器上,也可以达到每秒20000条。
Go的高性能真不是吹的,当然是要在足够的优化后:)