从词典查词到文本检索
十一假期大家过的还好吗?时间过得真快,距离上一次跟大家聊技术已经过了快三周了。老王很开心今天又能跟大家一起扯淡了,用一句通俗的话讲就是:老王想死你们了!今天准备跟大家聊的,乃是大名鼎鼎的文本检索技术。也就是大家天天都在用的“百度一下”。
为了简单,我们先从单词搜索开始,也就是类似于百词斩的查词功能。
想必大家或多或少都用过类似的功能,就是我们在查词框里输入几个字母或者中文,然后就能查找出我们想要的单词。那这个算法是如何实现的呢?其实有很多中方法,我们接下来一一介绍。这里为了更方便描述,我们就只介绍搜索英文的情况,中文含义的搜索其实类似,就不混着讲了~
在开始之前,我们先设定一个全局变量:假定有一个词典DICT,含有的单词:[good, bad, god, sad]。
方法一:暴力法
最容易让人想到的方法,就是写一个for循环,然后一个个的比较,看是否匹配,伪代码大概就是这样:
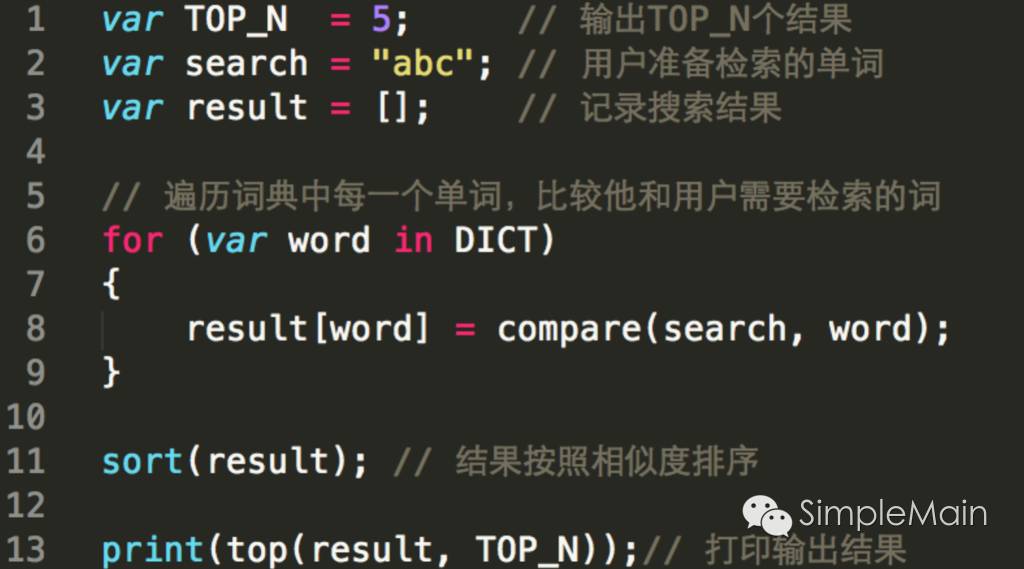
我们遍历词典中所有的单词,让每一个单词和我们待搜索的单词进行比较,看看他们之间的相似度,比较完了以后,就按照相似度排序,越像的排的越靠前。最后,我们将TOP-N的数据返回给用户。
这里面最关键的一个函数,就是compare。我们怎么比较两个单词的相似度呢?一般采用LCS(Longest Common Subsequence,最长公共子序列)算法。这个算法用来比较两个字符串含有的最多的相同字符,比如,same和some最长的公共子序列就是sme(same,some)。这个算法是一个动态规划算法,挺有意思,以后有时间可以专门跟大家做一个分享。
上述的查找算法虽然很精确,但是却有一个致命的问题,就是算法复杂度太高。如果我们有几万个单词,那么每次用户查询都要做一个几万次的for循环,然后循环里面还要做一次相似度比较,效率实在太低。
那有没有更好的方法呢?我们接着往下看。
方法二:Trie树(字典树)
想必好多朋友都听说过这个大名鼎鼎的字典树。老王模模糊糊的记得,当年去百度的时候,自己写了一个反作弊的匹配算法就用到了这个数据结构。那这个东东是怎么工作的呢?
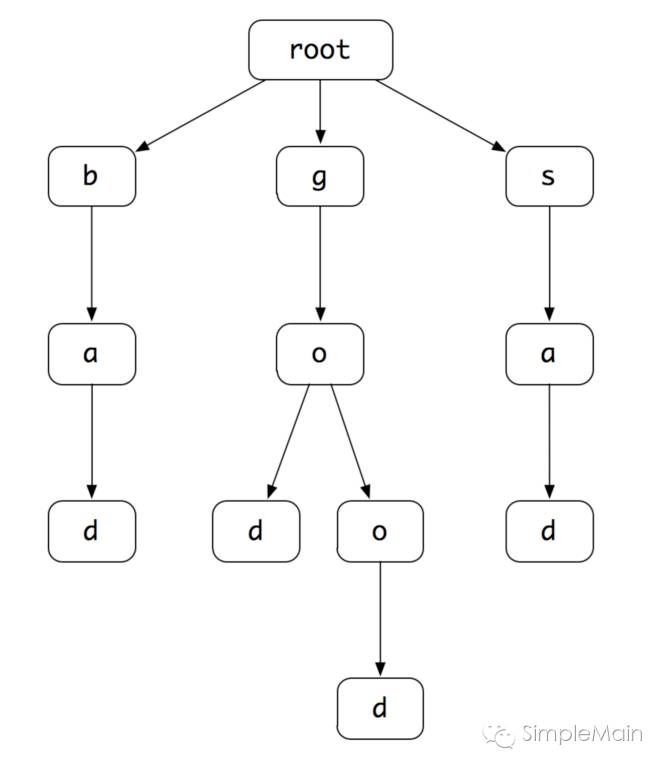
初始化的时候,我们构建一个根节点为空的树,然后我们将字典DICT中的单词,一个个的加入到这棵树中,单词的每一个字母挂接到对应的层次下,比如:good,就将g挂在root结点下,o挂接到g下…… 如此重复。便形成我们上面看到的这棵树。从root结点延任意一条路劲走到叶结点,都能形成我们字典中的单词。
那我们搜索的时候怎么做呢?
比如当用户输入go的时候,我们就从root结点开始,沿着这棵树一直往下走。依次走过root->g->o这三个结点。接下来他有两个子节点,我们就将这两个子节点对应的单词返回给用户,即:god、good。
大家看看,这种算法的复杂度一下就下降了,不用再做遍历。但是这个算法有一定的局限性:就是他只能做前缀匹配,也就是说他只能从开始做匹配,如果我们要匹配单词中间的一部分或者是模糊匹配,就很难实现。
不过,这种算法也可以做一些简单的改进,从而满足我们更多的需求。
我们在建树的时候,可以可以把每个单词做一下拆分,将每一个字符都作为起始字符进行建树。比如:good可以拆成4个单词:good, ood, od, d。然后分别将这些所谓的单词构建成Trie树。这样,我们即使搜索单词中间一部分,也能出对应的结果,就不需要强制用户从第一个字母开始输入。
那有朋友一定会问,这个规模会膨胀多少啊?我们只需要简单计算一下就能得出。比方说,我们平均每个单词的长度为10(老王大概统计了几万个单词,平均长度大概是8.4左右),那么我们所有需要构建的单词数就是DICT中单词数的10倍。如果我们常用单词约3万个,那么就只需要构建一棵大约30万个单词的树(这个数量级还是可以接受的)。
不过,即使通过上面的改进,我们还是比较难以实现模糊匹配的功能。比如,我们输入gd,字典树就不能检索出good或者god。
那还有没有其他的方法呢?
方法三:倒排索引
想必好多朋友对这个词都耳熟能详了吧。没错,这个算法就是我们现在检索用的最多的工业界方法。这个算法用了一个很简单的思想,解决了海量文本的索引问题。也就是百度、google做的事情。那具体怎么做的呢?跟着老王一起往下看吧。
我们之前讲的第一种方法(暴力法),对于单词没有任何预处理,数据的组织完全是按照单词本身去组织的,而没有按照用户的输入去组织,所以每次查询来了,都要重复的计算。而第二种方法(Trie树),则是做了一定的预处理,将单词拆分成字母,一定程度上按照用户输入的顺序来组织。所以,每次用户输入请求的时候,只需要做很小一部分计算,就可以得到结果。
那根据以上两种方式的启发,我们如果要很好的满足用户的需求,就应该将我们已有的数据按照用户的输入来组织,经过这样的预处理以后,等用户查询来的时候,我们就不会重复的去做计算了,对吧~
那倒排索引的思想也基本是这样:我们将每个单词都拆解成字母,然后根据用户输入的字母,将含有这些字母的单词都列举出来,然后看谁更符合用户的输入,就将谁返回。来看下图:
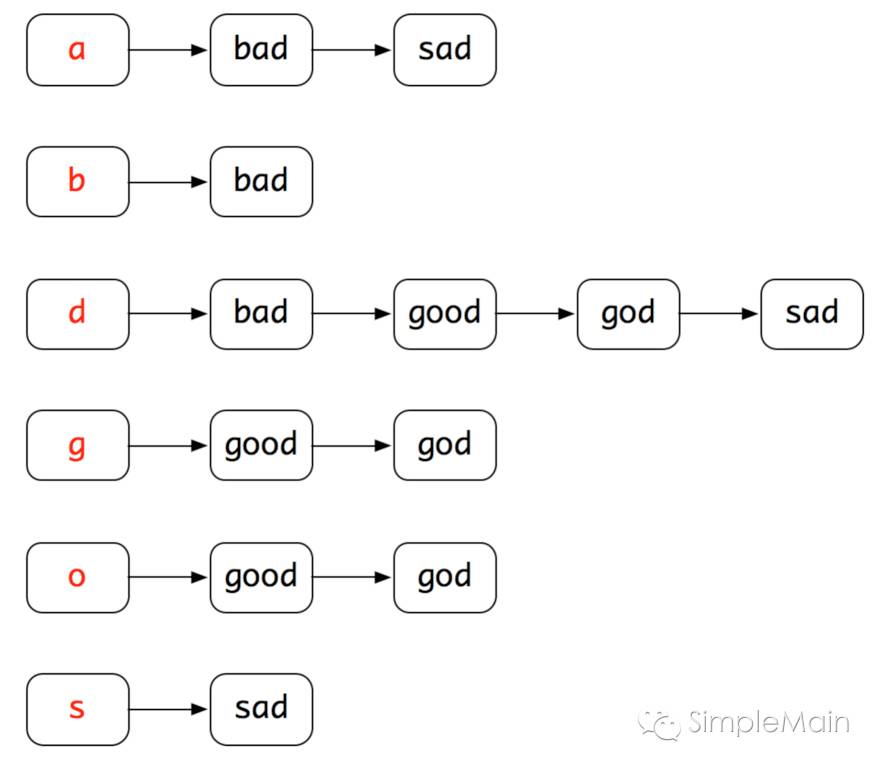
我们将每一个单词都拆解成单个单个的字母,然后将含有相同字母的单词挂接到对应的字母链上。如上图:bad就可以拆解成b、a、d三个字母,然后我们将bad这个单词分别挂接到字母b、a、d所在的链上。同理,对于其他单词也是。
这样,当用户输入b的时候,我们一下就能找到bad。如果用户输入bd,我们就可以将b链和d链的数据进行合并,将最符合条件的bad先输出,然后再输出其他几个有可能是结果的备选单词。
怎么样,是不是很简单啊。是的,这就是传说中的倒排索引。之所以称做倒排,是相对于bad->b-a-d这样的正排索引而言。
有了上述这个基本的逻辑以后,我们剩下的工作就是需要做结果优化。
1、多路归并计数。
比如,我们输入bd,那对于用户预期而言,结果bad肯定要比god要好,因为bad含有b和d两个关键字母,而god只有一个d。所以,我们要将检索的结果进行合并,看谁含有的关键字母更多,就应该往前面排。
这里用到了一个关键技术,就是多路归并。在算法和数据结构的课上,大家应该至少听说过这个算法。老王就不详细的来讲了。(记得当年刚到百度的时候,就参加了一个内部搞的一个算法优化大赛,做的就是多路归并算法优化,老王还得了前几名,哈哈哈~)
2、增加偏序关系。
上面讲了多路归并,那是不是出现字母越多,就应该排在越前面呢?我们看一个例子:当我们字典里有[god, dog, dot]这三个单词的时候,如果用户输入dog这三个字母的时候,根据上面多路归并的结果,god匹配3次,dog3次,dot2次,按道理说,我们就应该按照字典里的顺序输出god-dog-dot。但是,实际上比较好的一个结果可能是:dog-dot-god。为什么呢?因为用户输入的顺序很!重!要!
因此,我们除了要检查字母个数,还需要增加偏序关系,用于记录字母出现在单词中的位置。匹配结果的时候,要根据用户的输入顺序进行排序。具体实现的时候,我们可以在倒排拉链的时候,记录一下位置,最后归并的时候,对位置做一个打分,排序的时候,加入位置因素。
好了,以上讲了两种优化结果的方法。其实,还有很多地方要根据实际业务去优化,我们这里就不细讲了(不然这篇文章的字数真的就要过万了)。
那上面这个倒排索引的方法,是不是真的就很好了呢?如果你真的去写写代码,就会发现,还有一个巨大的坑儿在等着你!
对于a,e,i,o,u这几个元音字母而言,因为绝大多数单词都含有他们,所以他们的拉链会非常的长。如果有用户搜索a,那可能你的程序在很长时间内都没办法出结果。那怎么办呢?
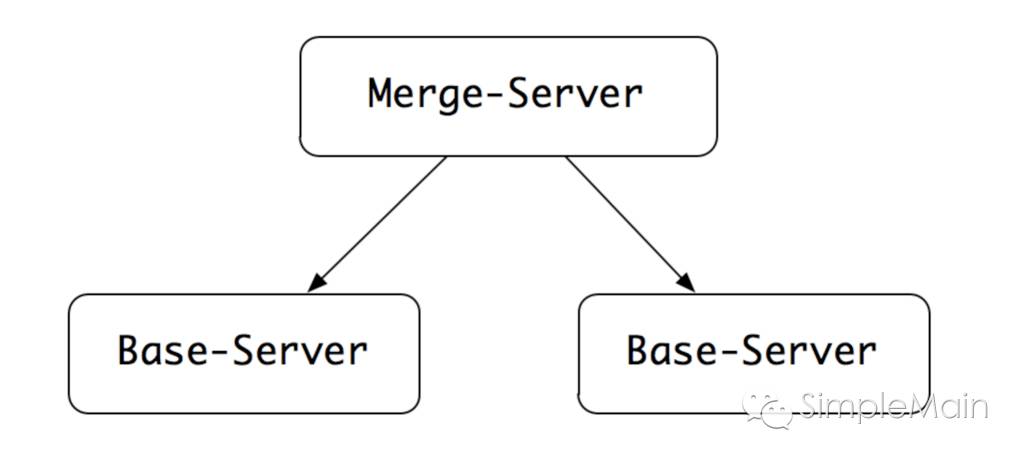
这个时候,我们就需要用到分布式了。我们可以将所有单词,随机的拆分成多个组。比如我们有1万个单词,拆分成10组。这样每一组单词,就只有大概1000个。比方说,原来含有字母a的单词大概有7000个,这样拆分以后,每个组里面就只有700个左右的单词含有字母a。因此每个组里面,字母a的拉链就只有700个左右的元素。
接下来,我们将每个组的单词放到一台服务器上,搜索的时候,每台服务器都进行检索。完成后,将TOP_N的结果上报给一个合并服务器,由他再做一次合并。这样,我们是不是就可以规避元音字母拉链过长的问题了呢。
好了,以上就是我们关于单词检索的算法。大家觉得怎么样呢?
除了单词搜索,我们在现实中还经常用到搜索好友、搜索文本内容等东东,对应的就是微信的好友搜索和百度的文本搜索。那这些东东在基础方法上都是上述的一个思想:元素拆分 + 倒排索引 + 合并优化。只不过,在每一个维度上都做了很多优化。比如:文本搜索中,整篇文章就像是一个单词,而文章中的词组就像是单词的字母,用词组作为倒排拉链的基础元素。那最难的就是分词,特别是中文分词,就是一个专门的课题。如果分词分的不好,那么检索的结果就会很差。以后找机会,老王也可以跟大家一起聊聊分词这个话题。
而倒排索引和结果合并,也是有很多地方需要优化的。比如,实时性强的文本(比如新闻),就需要按时间顺序来建立排序的索引。对于广告而言,可能价格就更重要。
好了,今天的内容大家都看懂了嘛?如果对老王的文章感兴趣,就请继续听老王扯淡吧。老王将文章做了分类,放到了自己搭的网站上,大家可以去上面看看www.ft12.com