使用深度学习方法实现面部表情包识别
1、动机
人类面部表情丰富,但可以总结归纳为 7 类基本表情: happy, sad, surprise, fear, anger, disgust, and neutral。面部表情是通过面部肌肉活动表达出来,有些比较微妙且复杂,包含了大量内心活动信息。通过面部表情识别,我们能简单而低成本地度量出观众/用户对内容和服务的态度。例如,零售商使用这些度量评估客户的满意度。健康医疗提供商能在治疗的过程根据病人的表情状态来提高服务。娱乐厂商能够监控观众的喜欢来持续的生产优质的内容。
“2016 is the year when machines learn to grasp human emotions” --Andrew Moore, the dean of computer science at Carnegie Mellon.
训练过的人类很容易读懂其他人的情绪。事实上,只有 14 个月大的婴儿就可以区别出 happy 和 sad 的区别。但是计算机能够比人类在识别情绪上做的更好吗?为了找到答案,我们设计一个深度神经网络使得机器可以读懂人类情绪。换句话说,给机器以“眼”识别面部表情。
2、语料数据
训练模型的数据集使用的是 Kaggle 面部识别挑战赛的数据集(2013 年)。它由 35887 张面部图片组成,48x48像素灰度图片,标注为 7 类基本表情: happy, sad, surprise, fear, anger, disgust, and neutral。
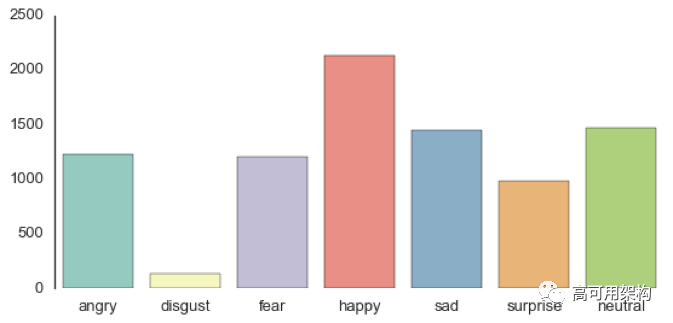
图 1 An overview of FER2013
当作者分析语料数据集时,发现“disgust”分类相对于其它分类不均衡(只有113 张样本)。作者将两类相似的情感(disgust 和 anger)合并起来。为了防止数据倾斜,作者构建一个数据生成器 fer2013datagen.py [1],该生成器很容易分割训练集和保留数据集。本例使用 28709 张面部图片作为训练集,余下的图片作为测试集和验证集(每个数据集 3589 张)。这样我们获得了 6 类均衡的数据集,见图2,包含 happy, sad, surprise, fear, anger, and neutral。
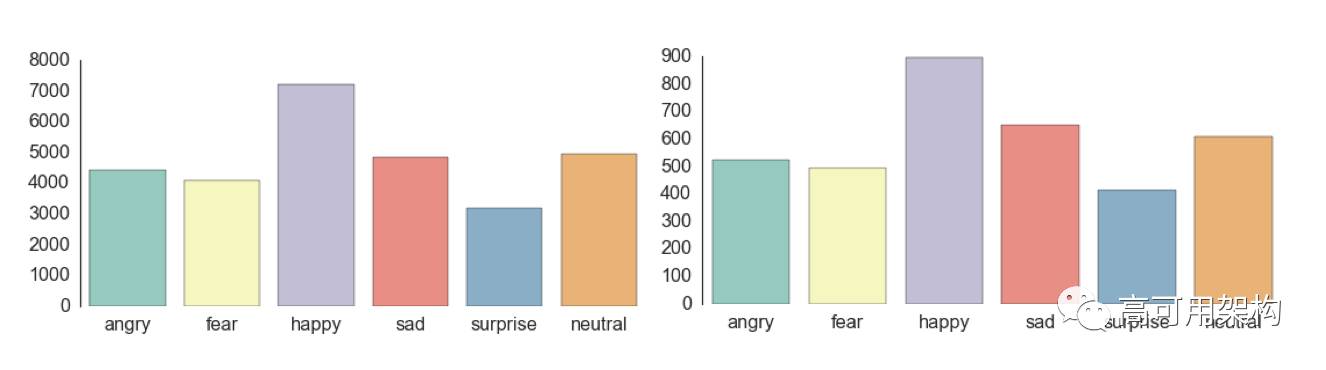
图 2. Training and validation data distribution.
3、算法模型

图3. Mr. Bean, the model for the model.
深度学习在计算机视觉上是非常流行的技术。本文选择卷积神经网络(CNN)层作为构建基础创建模型架构。CNN 是有名的模仿人脑工作的模型。本文使用憨豆先生的图片作为示例来解释如何将图像赋值给卷积神经网络模型。
典型的卷积神经网络包涵输入层,卷积层,稠密层(比如,全联接层)和输出层(见图4)。这些层按序组合,在 Keras [2] 中,使用 Sequential() 函数创建模型,再把其它层加入进来。
3.1 输入层
输入层需要预处理,输入固定维度的数据。所以图片需先预处理再传入输入层。作者使用 OpenCV(计算机视觉库)做图像面部识别。OpenCV 的 haar-cascade_frontalface_default.xml 文件包含预训练的过滤器,使用 Adaboost 算法能快速找到面部并裁剪。
使用 cv2.cvtColor 函数将裁剪面部图片转化为灰度图,并使用 cv2.resize 改变图片大小为 48x48 像素。处理完的面部图片,相比于原始的(3,48,48)三色 RGB 格式“瘦身”不少。同时也确保传入输入层的图片是(1,48,48)的 numpy 数组。
3.2 卷积层
numpy 数组传入 Convolution2D 层,指定过滤层的数量作为超参数。过滤层(比如,核函数)是随机生成权重。每个过滤层,(3,3)的感受野,采用权值共享与原图像卷积生成 feature map。
卷积层生成的 feature map 代表像素值的强度。例如,图5,通过过滤层1 和原始图像卷积生成一个 feature map,其它过滤层紧接着进行卷积操作生成一系列 feature map。
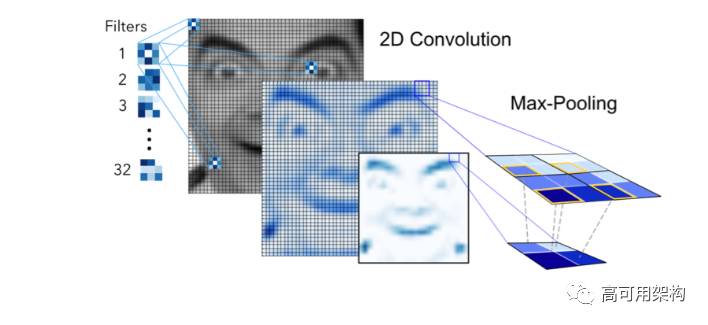
图 5. Convolution and 1st max-pooling used in the network
池化(Pooling)是一种降低维度的技术,常用于一个或者多个卷积层之后。池化操作是构建 CNN 的重要步骤,因为增加的多个卷积层会极大的影响计算时间。本文使用流行的池化方法 MaxPooling2D,其使用(2,2)窗口作用于 feature map 求的最大像素值。池化后图像降低 4 个维度。
3.3 稠密层
稠密层(比如,全联接层)是模仿人脑传输神经元的方式。它输入大量输入特征和变换特征,通过联接层与训练权重相连。
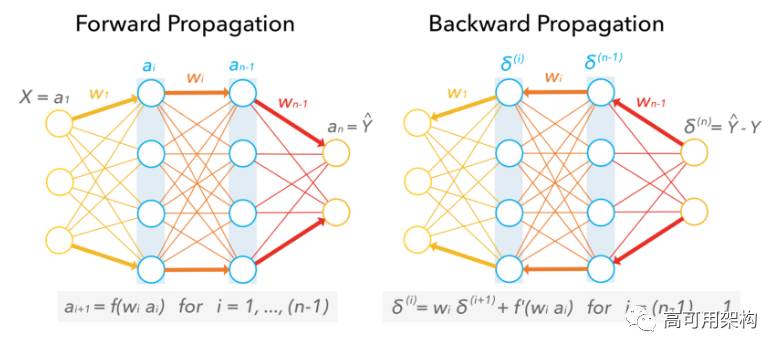
图 6. Neural network during training: Forward propagation (left) to Backward propagation (right).
模型训练时权重前向传播,而误差是反向传播。反向传播起始与预测值和实际值的差值,计算所需的权重调整大小反向传回到每层。采用超参数调优手段(比如,学习率和网络密度)控制训练速度和架构的复杂度。随着灌入更多的训练数据,神经网络能够使得误差最小化。
一般,神经网络层/节点数越多,越能捕捉到足够的信号。但是,也会造成算法模型训练过拟合。应用 dropout 可以防止训练模型过拟合。Dropout 随机选择部分节点(通常,占总节点数的百分比不超过 50%),并将其权重置为 0。该方法能有效的控制模型对噪声对敏感度,同时也保留架构的复杂度。
3.4 输出层
本文的输出层使用 softmax 激励函数代替 sigmoid 函数,将输出每类表情的概率。
因此,本文的算法模型能显示出人脸表情组成的详细组成概率。随后会发现没必要将人类表情表示为单个表情。本文采用的是混合表情来精确表示特定情感
注意,没有特定的公式能建立一个神经网络保证对各种场景都有效。不同的问题需要不同的模型架构,产生期待的验证准确度。这也是为什么说神经网络是个“黒盒算法”。但是也不要太气馁,模型训练的时间会让你找到最佳模型,获得最大价值。
3.5 小结
刚开始创建了一个简单的 CNN 深度学习模型,包括一个输入层,三个卷积层和一个输出层。事实证明,简单的算法模型效果比较差。准确度 0.1500 意味着仅仅是随机猜测的结果(1/6)。简单的网络结构导致不能有效的判别面部表情,那只能说明要“深挖”。。。

下面稍微修改下三部分的组合,增加模型的复杂度:
卷积层的数量和配置
稠密层的数量和配置
稠密层的 dropout 占比
使用 AWS 的 GPU 计算(g2.2xlarge)训练和评估组合的算法模型。这次极大的减少了训练时间和模型调优的效率。最后的网络模型是九层,每三层卷积层接着一个 max-pooling 层,见图 7。

图 7. Final model CNN architecture.
4、模型验证

4.1 结果
最后的 CNN 模型交叉验证准确度是 58%,其具有积极意义。因为人类面部表情经常由多个基本表情组合,仅仅用单一表情是很难描述。本例中,当训练模型预测不准确时,正确的标签一般是第二相似的表情,见图 8(浅蓝色标签)。

图 8. Prediction of 24 example faces randomly selected from test set.
4.2 分析
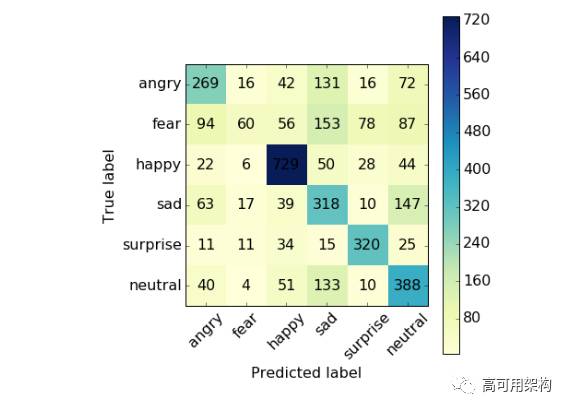
图 9. Confusion matrix for true and prediction emotion counts.
仔细看下每个表情的预测结果。图 9 是测试集的模型预测的混淆矩阵。矩阵给出表情预测的数量和多分类模型的效果展示:
该模型很好的鉴别出正表情(happy 和 surprised),预测准确度高。大约 7000 张训练集中,happy 表情的准确度达到 76.7%。surprised 表情预测准确度为 69.3%。
平均意义上讲,本例的神经网络模型对负表情的预测效果较差。sad 表情只有 39.7% 的准确度,并且该网络模型频繁的误判别 angry、fear 和 neutral 表情。另外,当预测 sad 表情和 neutral 表情时经常搞混,可能是因为这两个表情很少出现。
误分类预测小于 3 的频率
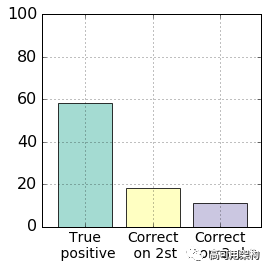
图 10. Correct predictions on 2nd and 3rd highest probable emotion.
4.3 计算机视觉
随着池化层数量的增加,下游神经网络管道的 feature map 越来越抽象。图 11 和图 12 可视化第二次和第三次 max-pooling 池化层后的 feature map。
分析和可视化卷积神经网络内层输出的代码见 [3]
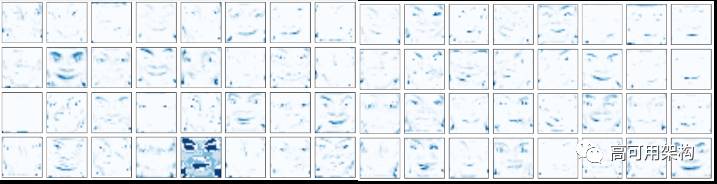
图 11. 第二个 max-pooling 池化层后的 CNN (64-filter) feature maps
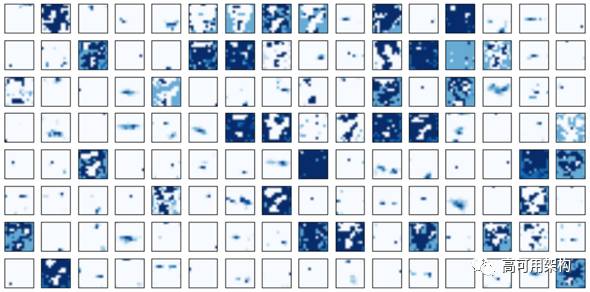
图 12. 第三个 max-pooling 池化层后的 CNN (128-filter) feature maps
关于作者
Jostine Ho 是数据科学家和深度学习研究者。她感兴趣于计算机视觉和自动化解决现实世界中具体问题。她毕业于德克萨斯大学奥斯汀分校,取得石油系统工程专业硕士学位。
参考
"Dataset: Facial Emotion Recognition (FER2013)" ICML 2013 Workshop in Challenges in Representation Learning, June 21 in Atlanta, GA.
"Andrej Karpathy's Convolutional Neural Networks (CNNs / ConvNets)" Convolutional Neural Networks for Visual Recognition (CS231n), Stanford University.
Srivastava et al., 2014. "Dropout: A Simple Way to Prevent Neural Networks from Overfitting", Journal of Machine Learning Research, 15:1929-1958.
Duncan, D., Shine, G., English, C., 2016. "Report: Facial Emotion Recognition in Real-time" Convolutional Neural Networks for Visual Recognition (CS231n), Stanford University.
相关链接
https://github.com/JostineHo/mememoji/blob/master/src/fer2013datagen.py
https://keras.io/models/sequential/
本文作者 Jostine Ho,由侠天翻译,转载请注明出处,技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。
侠天,专注于大数据、机器学习和数学相关的内容,并有个人公众号:bigdata_ny 分享相关技术文章。




