通过全文相似度来寻找相同或相似的代码
最近笔者在职的公司在不断的做App的包瘦身工作, 身边的同事们也研究出了各种各样实用的工具来辅助加快包瘦身的进程。在这么一个大环境下, 笔者突然又冒出一个很无聊的工具想法
通过文本匹配来寻找相似的方法函数
笔者给这个小工具取了一个非常传神且牛逼的名字 - SameCodeFinder
和上一个查找Block的无聊的小工具RiskBlockScanner类似, 这个工具笔者觉得也是一个应用面相对比较小的一个工具, 所以笔者自嘲无聊的小工具哈~
笔者自认为这个是一个无聊的小工具, 但是还是坚持把它开发出来了, 因为笔者坚信:
任何一个无聊小众的作品, 在合适的时机总是能够帮助到合适的人的!
笔者开发这个小工具除了因为笔者相信这个工具肯定能够帮助到部分人群以外, 还有另外一个目的是督促自己不要停止学习的步伐哈~
起源-辅助研发自查
查找相似代码想法的起源是因为笔者在在职的公司项目处于包瘦身的大环境下。在这个大环境下, 笔者身边的一名同事发明了基于otool和linkmap分析查找无用方法的工具, 该工具在Github上有个类似的开源脚本项目objc_cover。与此同时, 笔者的另外一名同事发表了一种基于Clang来查找无用方法的博文。
受这两位同事的影响, 笔者就在想自己能搞什么和他们不一样点的工具么。因为笔者之前用文本扫描的方式搞了一个简易的快速Block检查脚本, 笔者就在想能不能通过类似的手段写一个类似的程序。笔者想借鉴《基于Clang来查找无用方法》的思路进行扩展, 因为该文章里提出了一种将文本内容Hash后进行内容比较, 判断方法是否完全重合的思路。
笔者基于该思路进行扩展, 设想能不能不止比较“完全相同”的方法, 还能比较相似的方法。顺着这个思路发现了Google的全文搜索相似度比较的一种算法simhash[7, 8]。
Simhash
关于simhash的介绍引用博文《simhash算法原理及实现》 里的介绍
simhash是google用来处理海量文本去重的算法。 google出品,你懂的。 simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
上述引用其实有点不完全正确, simhash貌似并不是Google出品的, 第一作者的邮箱后缀明明是普林斯顿大学好不好~ 不过Google将其应用到了网络爬虫并发表了一篇文章哈~
PS: 想了解详情? 阅读Paper去… =。=
《simhash算法原理及实现》 针对simhash梳理了简易的原理介绍以及使用判断距离的汉明距离, 可以便于读者快速了解, 但是如果大家想要了解更深层次的实现, 可以去阅读原版paper《Detecting Near-Duplicates For Web Crawling》和《Similarity estimation techniques from
rounding algorithms》。
原理简析
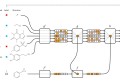
simhash的生产步骤可以分为如下:
提取目标文本的关键字feature和权重weight, 并成对存储
如果不知道怎么提取的同学, 可能需要稍微了解全文搜索相关的知识
将提取出来的关键字进行传统Hash, 输出二进制的值
将每一个关键字提取的Hash按位进行运算, 如果当前位是1, 则增加对应的权重; 如果当前位是0, 增减少当前对应的权重;
将最后得出来的hash值, 如果大于等于1, 则当做1处理; 负数和0当做0处理, 得出最终的二进制值
上述步骤可以简化为下图, 此图引用了我的数学之美系列二 —— simhash与重复信息识别中的图

汉明距离
simhash是一种局部敏感Hash。因此可以利用汉明距离去衡量simhash的相似度。
引入Wikipedia的汉明距离介绍:
In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different.
字面上意思好像就是两个字符串在不一样字符个数的数量, 在我们现在的应用场景就是统计1或者0的个数, 然后他们的个数差就是距离了。。。一般搜索引擎的历史经验默认是3
PS: 别问我怎么知道的3的, 我也是从博客里看来的, 没有数据依据
寻找相似的代码
寻找完全相似的文件
针对上述理论, 只要是一个文档都可以计算出两者的汉明距离, 利用汉明距离来就可以衡量两个文档的相似度了。笔者在这里目前没有做太多的工作, 只不过过滤了文档的后缀, 让相当类型的文档进行相互的比较。
寻找相似的文件和寻找相似的代码文件, 其实本质上差距不大。代码文件有一些特性, 例如前面的声明和引用都有一列类似的地方, 如果在进行simhash计算处理前能够提前对代码文件进行预处理的话, 能够大幅度的提高整个代码文件相似度计算的精度。
PS: 鉴于思路的完善性和时间成本, 笔者还没有针对代码进行预处理
寻找雷同方法函数
既然利用simhash以及汉明距离可以计算两个文档的相似度, 然自然可以缩小范围计算两个函数方法的相似度。那么问题的关键就在于怎么样才能提取到合适正确的方法函数内容
笔者目前使用的是文本扫描匹配的方式, 但是笔者的同事有提出一种是基于clang插件来提取编译器预处理之后的内容进行hash比较的可行思路。无奈鉴于实现成本和插件无法独立运行的方面考虑, 暂时采用的直接扫描匹配文本的方式进行比较。
目前笔者采取的提取方法体方法是:
用正则匹配获取方法起始行
从起始行开始记录左右括号的格式, 并且将起始行开始的所有字符串记录
当左右括号的个数相互抵消的时候默认当做匹配整个方法, 保存整个字符串
鉴于方法匹配需要根据语法实现, 所以目前只能根据每个语言的语法特性进行截获, 目前SameCodeFinder)仅支持Object-C和Java。
语法特性局限了脚本的可扩展性, 步骤一的正则需要和后缀匹配, 步骤二的左右括号在某些语言下不适用, 只能利用发现下一个方法起始行作为步骤三的结束步骤。
Java目前采用正则:
1
ur"(public|private)(.*)\)\s?{"
Object-C目前采用正则:
1
ur"(\-|\+)\s?\(.*\).*(\:\s?\(.*\).*)?{?"
排序
无论是寻找雷同的文件还是寻找雷同的方法, 最后计算出的Hash结果都是N * N个的, 那么怎么展示计算的结果呢? 如果把所有的结果都展示出来, 那明显可阅读性太低。
目前采用的逻辑是:
N * N 中第一个N只找出距离最小的第一个返回, 这样过滤结果只保留N个
将第一步过滤返回的N个结果按照从小到大的方式进行排序
此外,在执行排序的步骤1和步骤2之间, 都可以添加一个最大距离过滤, 默认不超过20, 可以大幅度减少步骤1和步骤2的计算排序过滤时间。
开源实现
笔者基于上述思路以及现成的工具, 利用python脚本花了2天时间去高速实现了一个简易的python脚本, 并开源到了Github上。
访问地址: SameCodeFinder
目前开源的版本可能因为笔者使用不当或者开源python版本的simhash的计算太过耗时, 因此在性能上存在一定的性能问题, 计算整个较大的工程需要花费不少的时间(计算一个大型工程是分钟级别的)。
笔者会在之后寻找突破方法来提高这方面的计算性能~
总结
SameCodeFinder可以帮助大家寻找相似或者完全重叠的方法以及类, 极大程度上可以辅助大家寻找可以复用的代码。SameCodeFinder的实现思路都是借用Google的全文相似度比较的现成实现, 并没有什么创新, 但是脚本化和针对语种设计的方法识别, 能够帮助大家节省不少直接利用simhash去实现的成本。
PS: 个人水平有限, 有错误之处请大家及时指出, 随时交流哈~
参考文献
GS Manku, A Jain, A Das Sarma. Detecting Near-Duplicates For Web Crawling. International Conference on World Wide Web. International Conference on World Wide Web. 141-149. 2007.
M. Charikar. Similarity estimation techniques from
rounding algorithms. In Proc. 34th Annual Symposium
on Theory of Computing (STOC 2002), pages
380–388, 2002.