短网址网站开发运维的经验分享与总结
所谓隔行如隔山,不干这一行,不懂这一行的难。
随着用户的逐渐增多,ft12短网址的日访问PV终于突破了50万,但其中掺杂着一半喜与一半忧。喜的是自己的短网址站得到了广大用户的认可,忧的是如何处理这么大的流量。期间,服务器分别经历了内存报警、IO 瓶颈后,CPU爆表等等问题,几乎使短连接站瘫痪。
前景交代
短网址由于其特殊性,所以非常难盈利,因此硬件特别寒碜(各别土豪站长可以直接无视这一条),各方面的投入,如人力、技术、时间等也不能和其他大网站比。
用来运营网址缩短网站的服务器采用的硬件是: 阿里云入门型,2G内存,双核弹性ECU,后期又增加了一个 RDS关系型数据库替代原有的MYSQL数据库。
硬件成本计算:
既然项目本身基本没法带来收益,要生存就只能充分压榨硬件,大胆使用新技术。根据国内云的计费方式,一般收费的维度是
阿里云入门型的ECS每月200元(主要是带宽贵,我们选用的是5M的独立带宽)
由此我们做了对应的技术选型:
centos:这个不用解释了吧?windows系统可是资源大户
Nginx:下雨天,Nginx和centos更配^_^
RDS:性能好,热数据少内存开销也少,最主要的是能够实时备份,数据库的安全最重要
Redis:事实上RDS数据库的读写非常耗时耗力,通过Redis缓存进行读取,然后传递给RDS会减轻很多压力
nodejs(with coffeescript):后期新增,node.js 是天生的异步
supervisord:监控进程
来照张相——咔嚓 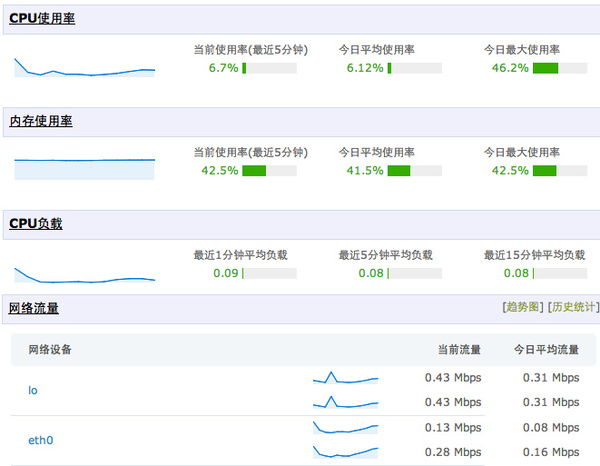
开发与运维
鉴于目前项目投入的开发和运维都只有我一个人,那就可以美其名曰:DevOps 啦。听上去是不是很高端大气国际化。
短链接的访问特征
二八法则基本适用(可以更夸张的说一九原则):不到20% 的 短链接 占用了 超过80% 的资源。
监控先行
很多小团队犯的第一个毛病就是不做监控,等到用户来告诉你网站无法打开的时候就太晚了。为了省事我们用了监控宝和阿里云监控(主要阿里云监控有免费短信)。
每次出现无法打开网站的状态时,都应该定位此次问题的原因。如果频次增加,就要考虑应对策略了。loadavg 很好地反应了系统的负载,可以判断是否硬件出现瓶颈。
如果是在事发时间,我们可以借助这些工具查看系统状态:htop(定位哪个进程的问题)、iftop(是否有异常的流量和ip)、iotop(定位 io 瓶颈)。此外就是看日志。
如果事发时在睡觉,那么就看监控历史记录。
经验总结一:硬盘太小(由于资金问题,服务器开始买的是乞丐版)
MongoDB在硬盘容量不够的时候会拒绝启动。而如果之前没有使用 lvm 这类工具,将无法快速扩展容量,而国内的云不像 Linode 那么智能地在后台提供容量的一键 resize(虽然这个功能曾把文件系统搞出错了)。后果很可能是停机几个小时。这时候,假设你真的不想去扩容服务器的硬盘,那么,请关闭NGINX以及MongoDB的日志,这是硬盘占用的大户。
经验总结二:最大打开文件描述符
异步模式下不可避免遇到新问题——最大打开文件描述符。我们先后遇上了 tornado 和 nginx 的最大打开文件描述符问题。 tornado 的表现为:CPU 100%,日志里出现500;Nginx 则在日志里报错,打开缓慢。
要避免此类问题,要做相应 ulimit 的设置。
用ulimit -n显示的只是当前会话的(!important)。正确做法是查看进程的 limits: cat /proc/{$pid}/limits
Nginx 的配置文件里还需要设置两个参数:
1 2 | worker_connections 9999; #根据自己的情况设置 worker_rlimit_nofile 60000; #根据自己的情况设置 |
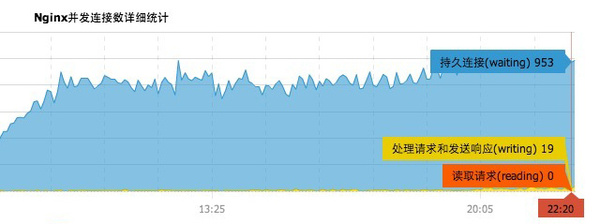
下图是 nginx 达到上限的监控图,很明显被卡在1000左右了 —— Linux 默认限制为 1024。
经验总结三:如果想要异步,请把Python换成nodejs
说实话,用 Python 来设计的过程可不是一个愉快的过程。为了避免潜在编码问题,我们使用了 python3。下面的问题是:
缺乏异步的支持:
Redis 异步驱动只支持 Python2(当然,等了大约半年后 tornado-redis 的作者终于更新了对 python3 的支持)。
不少组件仍然无法支持 python3,
pip install后直接报错的感觉就是:傻眼了。Bitly 的 asyncmongo 简直是没有文档,最后只能选了 Motor。
Tornado 本身的文档也不够详尽
后来一部分组件使用 nodejs 开发后,简直是相见恨晚,CoffeeScript 语法糖的表现也很出色。
经验总结四:不要选择MYSQL
数据库几乎是web应用里最关键的一部分,越是有大局观的技术人员越会谨慎选型。 事实上我们把所有压力都放 MongoDB 的做法还是过于激进了。
对于几千万张表的数据库,一点点的优化和改进,对性能的影响会非常大(一点也不夸张!)。一定要用发展的眼光去看待数据库,强烈建议在规划初期,就把数据库进行分表处理,减轻查询时间和CPU的占用
阿里云RDS 的范式化与反范式化。
几乎所有对 RDS一知半解的人都会告诉你不要用 SQL 的思维来思考RDS,要使用内嵌文档来实现需求。但是他们忘记告诉你,不断增长的内嵌文档将导致 IO 瓶颈(参考《深入学习 MongoDB》73页)。
事实上范式化和反范式化(内嵌文档)还有很多要考虑的因素。
复杂查询时 MongoDB 的无力
在面对需要计算的查询时,MongoDB 的 map-reduce 很慢;复杂情况下对内嵌文档处理有难度;Documents 比 MySQL 更少。年轻人,不要在 mysql 遇到问题时第一时间想到替换数据库。
就这个项目而言,统计部分要快速出多样报表时明显有难度。
不要等到着火了才想起 RDS数据库
如果 RDS 写入压力大,并且没有做分片,那么单纯加机器不会缓解写入压力。如果是读取压力倒有所帮助。
从单机到 replSet 起码需要锁住数据库。程序代码也需要修改。打算切换到 replSet 的话,需要提前做准备。
最后我们的做法是将频繁更新的数据放 redis,定时刷入数据库,效果很明显。
正确使用 Redis
控制内存,控制起步成本
如果你打算省钱的,就不要把所有东西都放 Redis 里,哪怕看上去数据量不大——时间久了也占了不少内存。而在 MongoDB 里只有热数据占内存。 二八法则也适用这种情况:热数据只占20%。
当然如果你是土豪请你走开!
不要用 pub/sub 做队列
如果不想丢失数据就不要用 pub/sub 做队列。进程重启时将丢失订阅管道的信息。你可以用 lpush 和 brpop 来实现队列。
受够阿里云了
如果被 DDOS 攻击怎么办?直接黑洞,至少半小时内服务器无法开动,直接气死你
为什么所谓的国际大品牌io性能能如此之差,读写大约 4-6M/s 的就到其瓶颈了
最后的忠告
多读书,争取站在巨人的肩膀上。